Towards Precise Scaling Laws for Video Diffusion Transformers
Yuanyang Yin ⋅ Yaqi Zhao ⋅ Mingwu Zheng ⋅ Ke Lin ⋅ Jiarong Ou ⋅ Rui Chen ⋅ Victor Shea-Jay Huang ⋅ Jiahao Wang ⋅ Xin Tao ⋅ Pengfei Wan ⋅ Di ZHANG ⋅ Baoqun Yin ⋅ Wentao Zhang ⋅ Kun Gai
2025 Poster
{kind=link}
Abstract
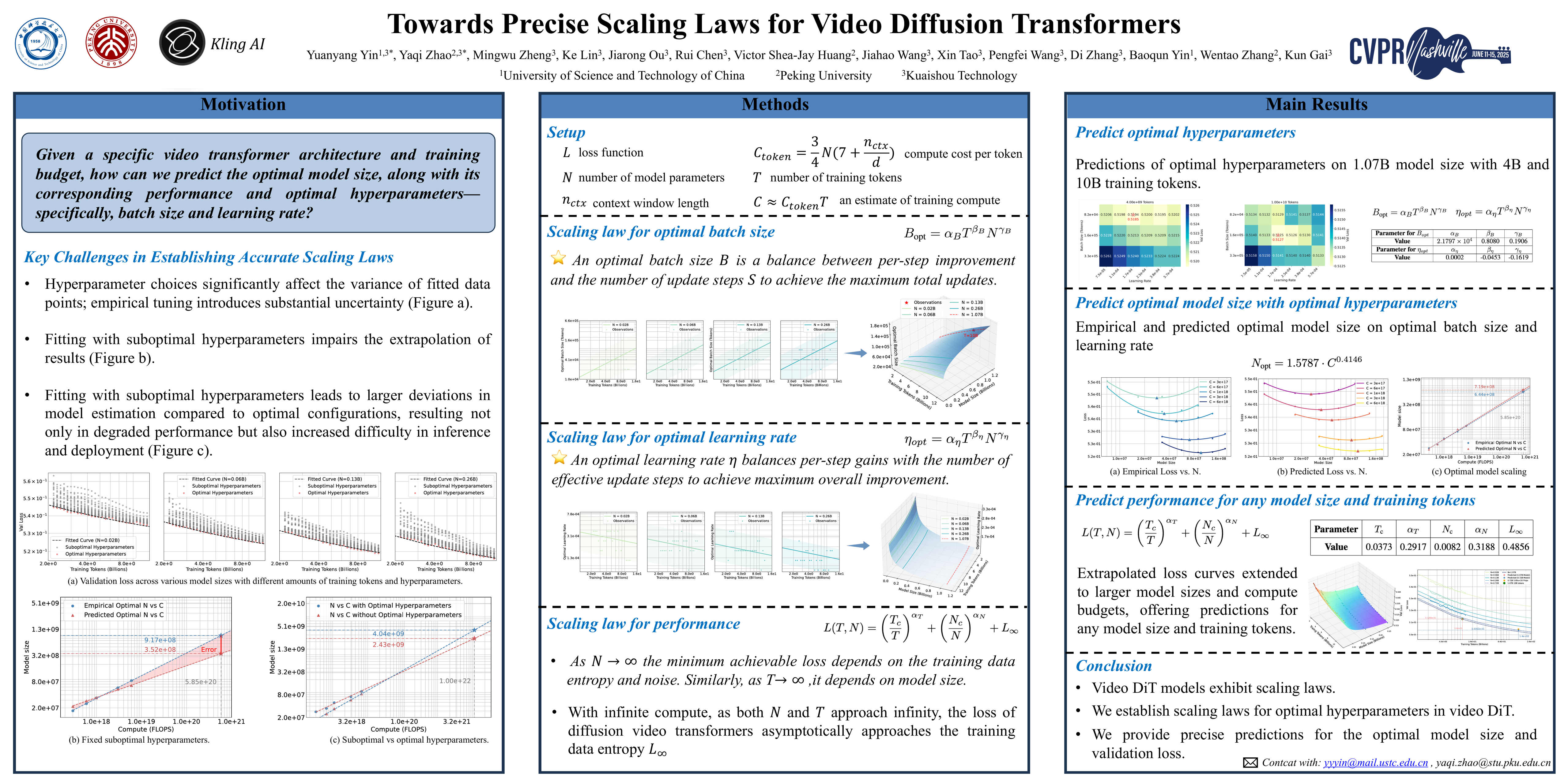
Achieving optimal performance of video diffusion transformers within given data and compute budgets is crucial due to their high training costs. This necessitates precisely determining the optimal model size and training hyperparameters before large-scale training. While scaling laws are employed in language models to predict performance, their existence and accurate derivation in visual generation models remain underexplored. In this paper, we systematically analyze scaling laws for video diffusion transformers and confirm their presence. Moreover, we discover that, unlike language models, video diffusion models are more sensitive to learning rate and batch size—two hyperparameters often not precisely modeled. To address this, we propose a new scaling law that predicts optimal hyperparameters for any model size and compute budget. Under these optimal settings, we achieve comparable performance and reduce inference costs by $40.1\%$ compared to conventional scaling methods, within a compute budget of $1e10$ TFlops. Furthermore, we establish a more generalized and precise relationship among test loss, any model size, and training budget. This enables performance prediction for non-optimal model sizes, which may also be appealed under practical inference cost constraints, achieving a better trade-off.
Chat is not available.
Successful Page Load