SMILE: Infusing Spatial and Motion Semantics in Masked Video Learning
{kind=link}
Abstract
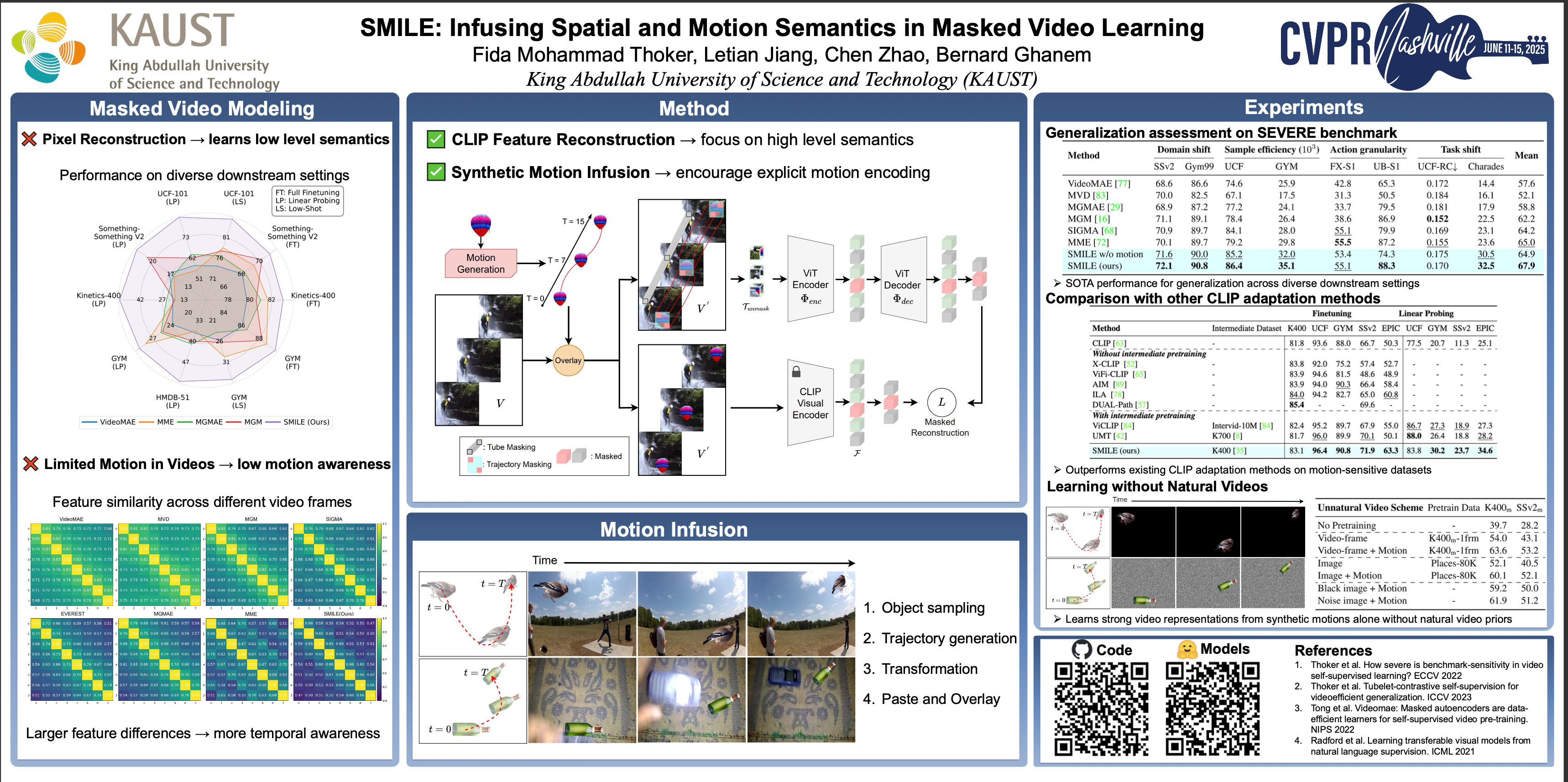
Masked video modeling, such as VideoMAE, is an effective paradigm for video self-supervised learning (SSL). However, they are primarily based on reconstructing pixel-level details on natural videos which have substantial temporal correlation, limiting their capability for semantic representation and sufficient encoding of motion dynamics. To address these issues, this paper introduces a novel SSL approach for video representation learning, dubbed as SMILE, by infusing both spatial and motion semantics. In SMILE, we leverage image-language pretrained models, such as CLIP, to guide the learning process with high-level spatial semantics. We enhance the representation of motion by introducing synthetic motion patterns in the training data, allowing the model to capture more complex and dynamic content. Furthermore, using SMILE, we establish a new video self-supervised learning paradigm, capable of learning robust video representations without requiring any video data. We have carried out extensive experiments on 7 datasets with various downstream scenarios. SMILE surpasses current state-of-the-art SSL methods, showcasing its effectiveness in learning more discriminative and generalizable video representations.