Event-Equalized Dense Video Captioning
Kangyi Wu ⋅ Pengna Li ⋅ Jingwen Fu ⋅ Yizhe Li ⋅ Yang Wu ⋅ Yuhan Liu ⋅ Jinjun Wang ⋅ Sanping Zhou
2025 Poster
{kind=link}
Abstract
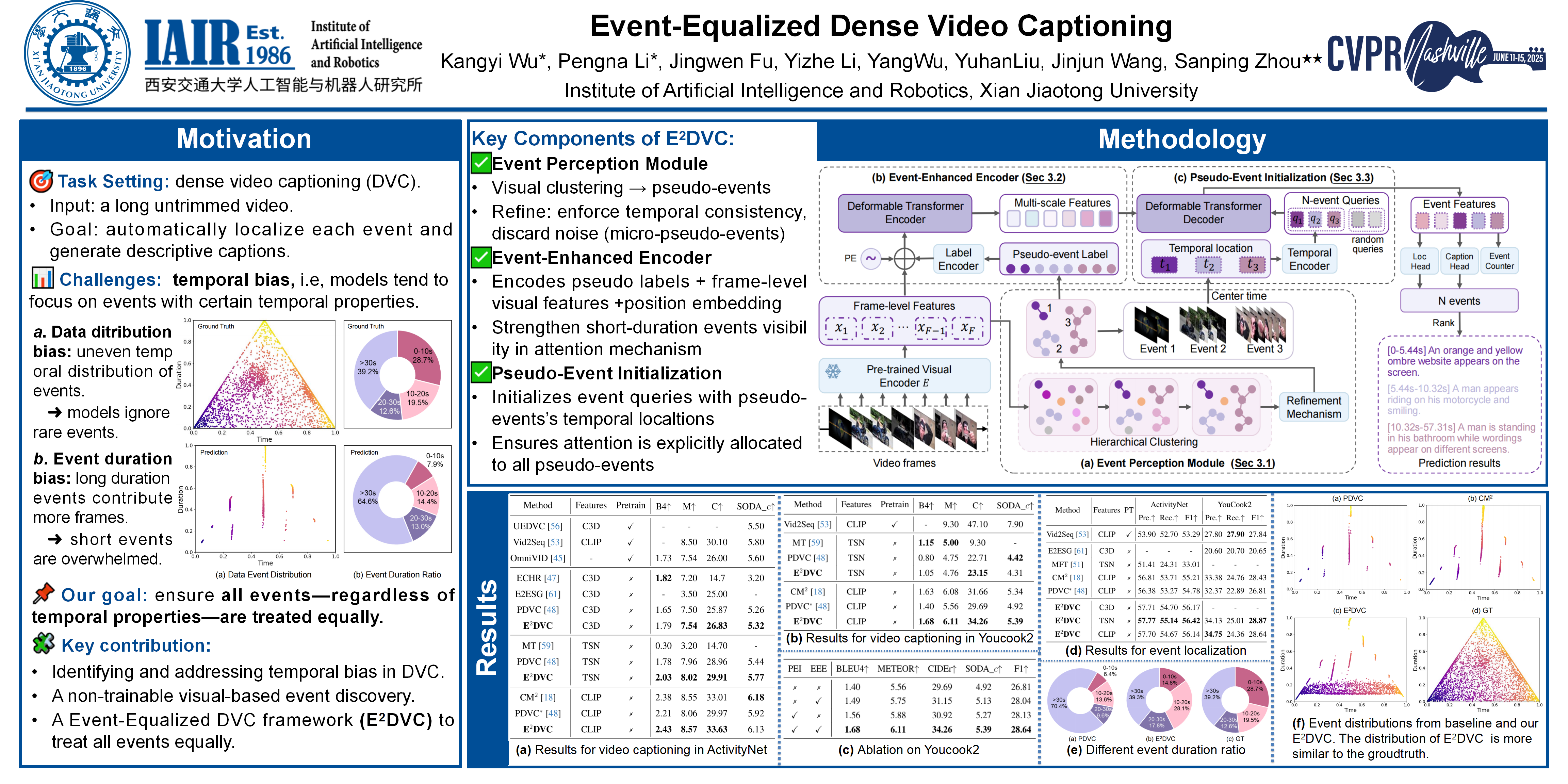
Dense video captioning aims to localize and caption all events in arbitrary untrimmed videos. Although previous methods have achieved appealing results, they still face the issue of temporal bias, i.e, models tend to focus more on events with certain temporal characteristics. Specifically, 1) the temporal distribution of events in training datasets is uneven. Models trained on these datasets will pay less attention to out-of-distribution events. 2) long-duration events have more frame features than short ones and will attract more attention. To address this, we argue that events, with varying temporal characteristics, should be \textbf{treated equally} when it comes to dense video captioning. Intuitively, different events tend to have distinct visual differences due to varied camera views, backgrounds, or subjects. Inspired by that, we intend to utilize visual features to have an approximate perception of possible events and pay equal attention to them. In this paper, we introduce a simple but effective framework, called Event-Equalized Dense Video Captioning(E$^2$DVC) to overcome the temporal bias and treat all possible events equally. Specifically, an event perception module(EPM) is proposed to do uneven clustering on visual frame features to generate pseudo-events. We enforce the model's attention to these pseudo-events through the pseudo-event initialization module(PEI). A novel event-enhanced encoder(EEE) is also devised to enhance the model's ability to explore frame-frame and frame-event relationships. Experimental results validate the effectiveness of the proposed methods.
Chat is not available.
Successful Page Load