Learning Temporally Consistent Video Depth from Video Diffusion Priors
{kind=link}
Abstract
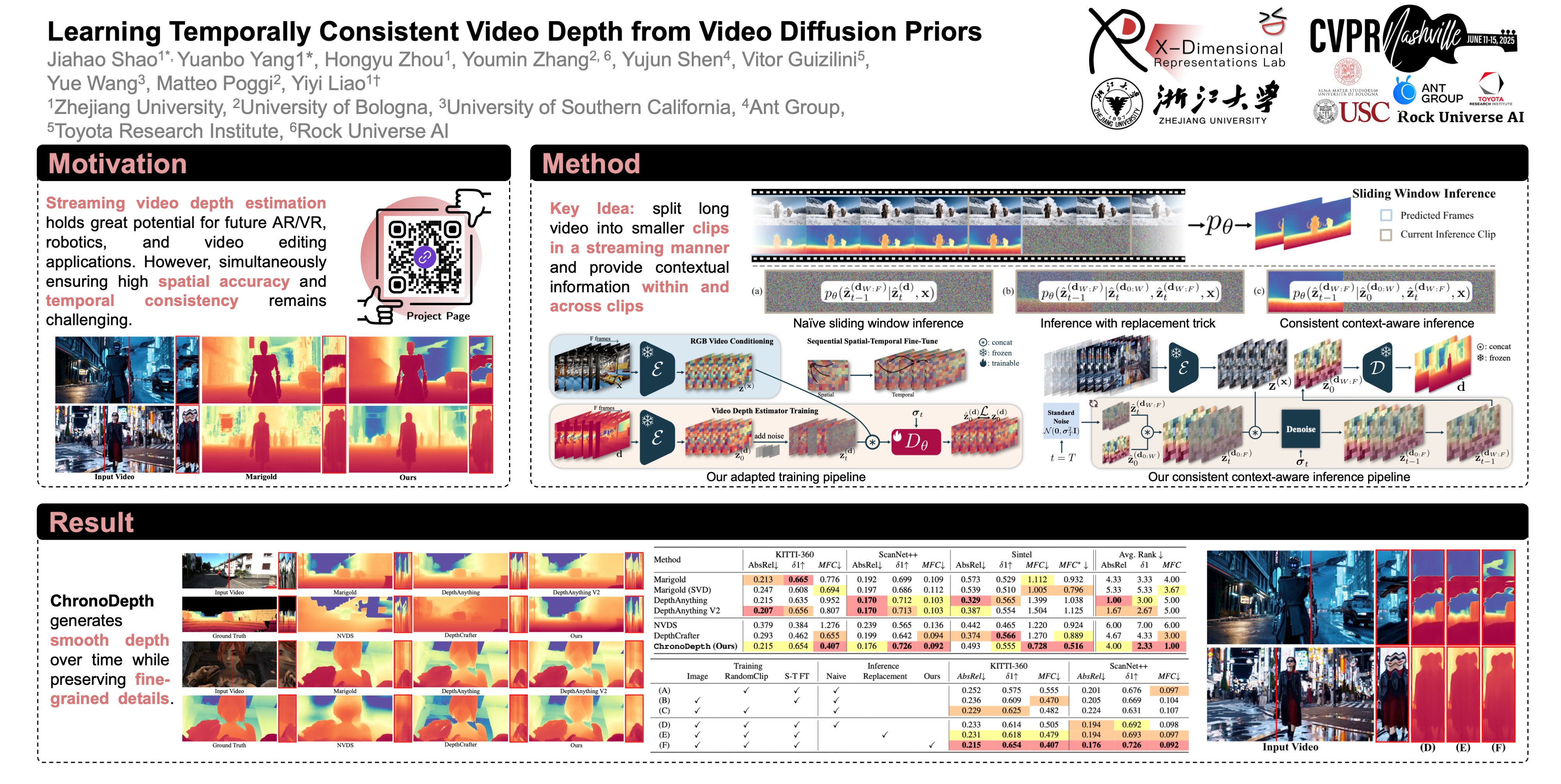
This work addresses the challenge of streamed video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. We argue that no contextual information shared between frames or clips is pivotal in fostering inconsistency. Instead of directly developing a depth estimator from scratch, we reformulate this predictive task into a conditional generation problem to provide contextual information within a clip and across clips. Specifically, we propose a consistent context-aware training and inference strategy for arbitrarily long videos to provide cross-clip context. We sample independent noise levels for each frame within a clip during training while using a sliding window strategy and initializing overlapping frames with previously predicted frames without adding noise. Moreover, We design an effective training strategy to provide context within a clip. Extensive experimental results validate our design choices and demonstrate the superiority of our approach, dubbed ChronoDepth.