SpatialLLM: A Compound 3D-Informed Design towards Spatially-Intelligent Large Multimodal Models
 Highlight
Highlight
{kind=link}
Abstract
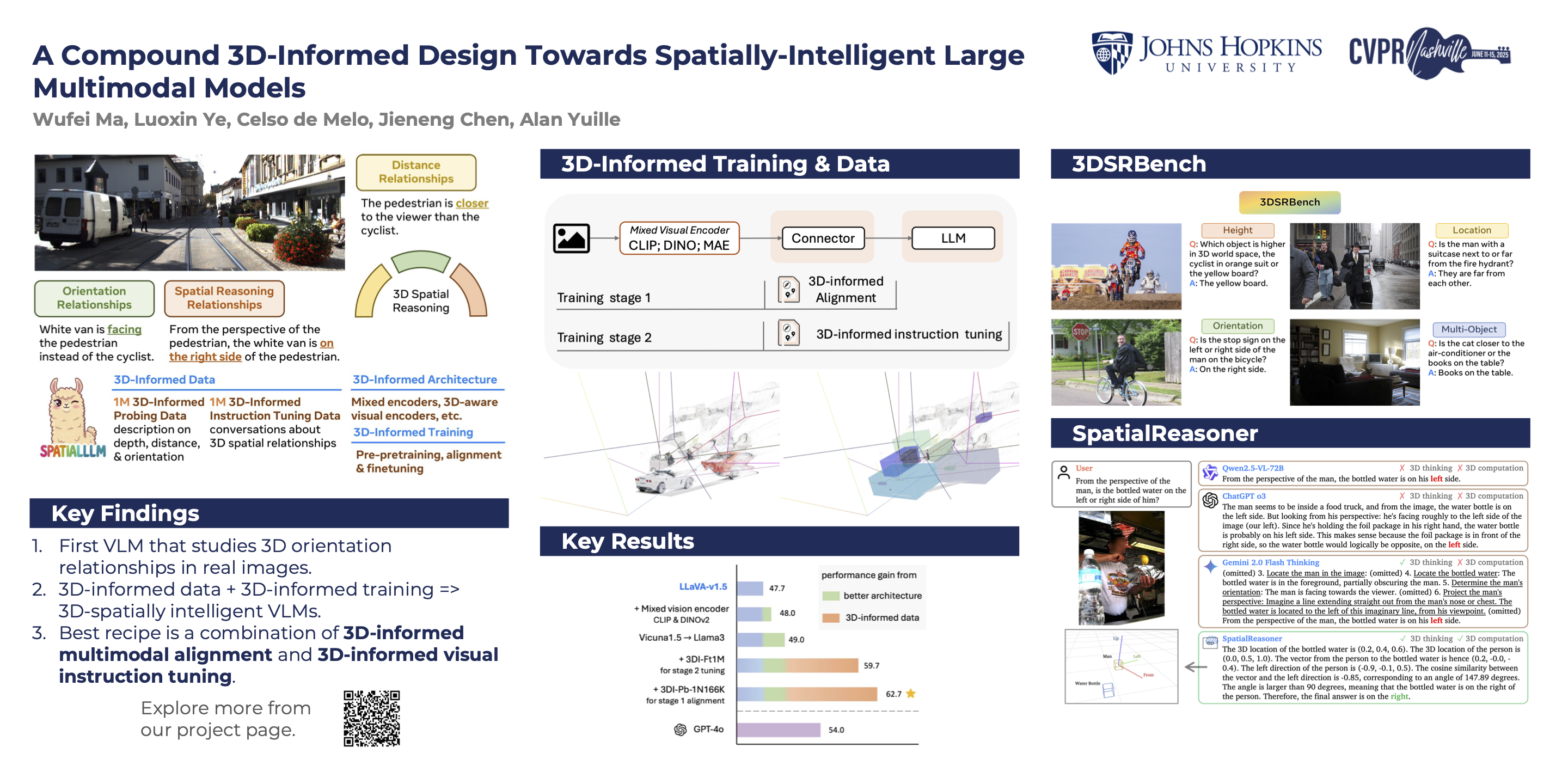
Humans naturally understand 3D spatial relationships, enabling complex reasoning like predicting collisions of vehicles from different directions. Current large multimodal models (LMMs), however, lack of this capability of 3D reasoning. This limitation stems from the scarcity of 3D training data and the bias in current model designs toward 2D data. In this paper, we systematically study the impact of 3D-informed data, architecture, and training setups, introducing 3DI-LMM, an LMM with advanced 3D spatial reasoning abilities. To address data limitations, we develop two types of 3D-informed training datasets: (1) 3D-informed probing data focused on object's 3D location and orientation, and (2) 3D-informed conversation data for complex spatial relationships. Notably, we are the first to curate VQA data that incorporates 3D orientation relationships. Furthermore, we systematically integrate these two types of training data with the architectural and training designs of LMMs, providing a roadmap for optimal design aimed at achieving superior 3D reasoning capabilities. Our 3DI-LMM advances machines toward highly capable 3D-informed reasoning, surpass GPT-4o performance by 8.7%. Our systematic empirical design and resulting findings offer valuable insights for future research in this direction.