Mamba-Adaptor: State Space Model Adaptor for Visual Recognition
{kind=link}
Abstract
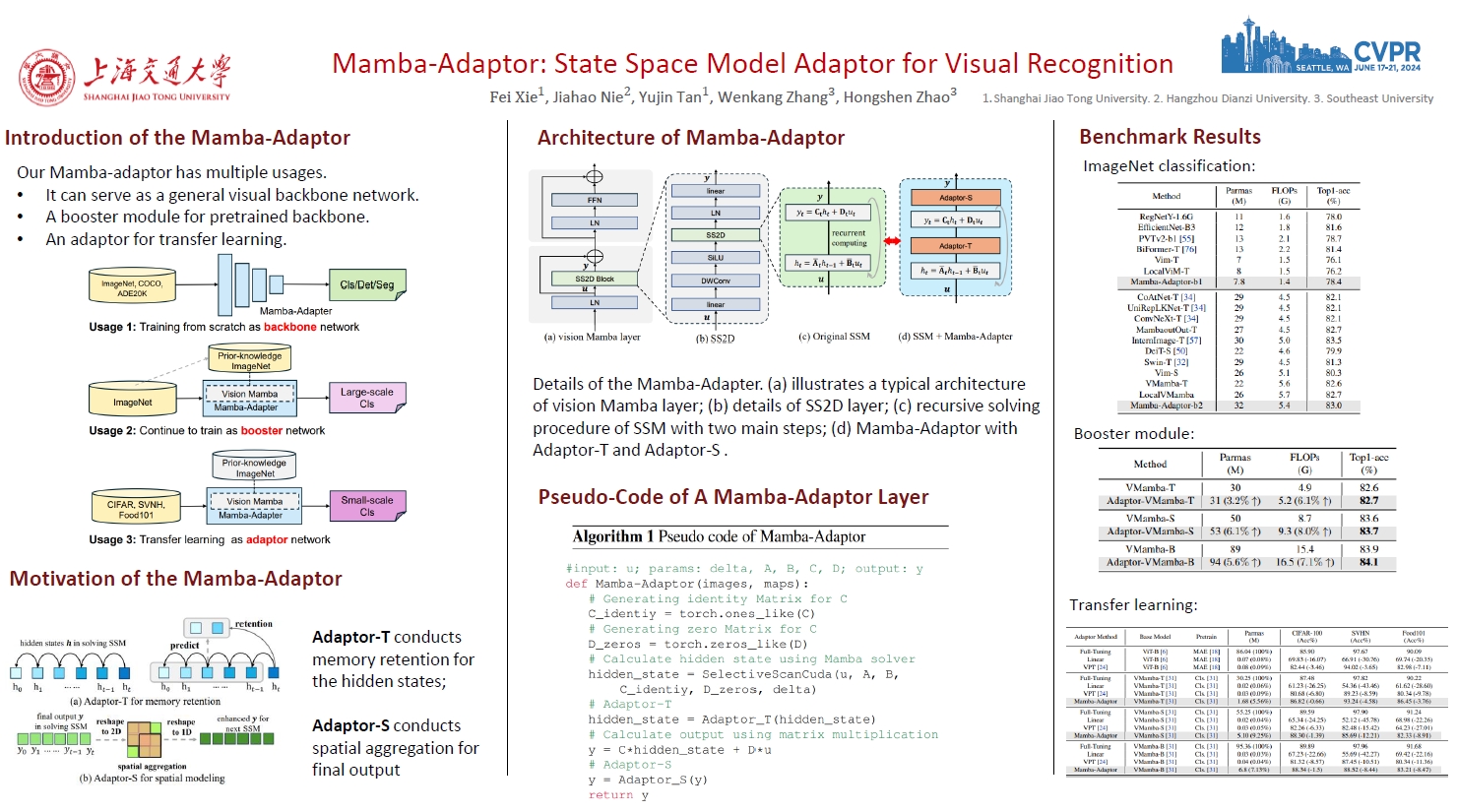
Recent State Space Models (SSM), especially Mamba, have demonstrated impressive performance in visual modeling and possess superior model efficiency. However, the application of Mamba to visual tasks suffers inferior performance due to three main constraints existing in the sequential model: 1) Casual computing is incapable of accessing global context; 2) Long-range forgetting when computing the current hidden states; 3) Weak spatial structural modeling due to the transformed sequential input. To address these issues, we investigate a simple yet powerful vision task adapter for Mamba models, which consists of two functional modules: Adaptor-T and Adapator-S. When solving the hidden states for SSM, we apply a casual prediction module Adaptor-T to select a set of learnable locations as memory augmentation feature states to ease long-range forgetting issues. Moreover, we leverage Adapator-S, composed of multi-scale dilated convolutional kernels, to enhance the spatial modeling and introduce the image inductive bias into the feature output. Both two modules can enlarge the context modeling in casual computing, as the output is enhanced by the inaccessible features. We explore three usages of Mamba-Adaptor: A general visual backbone for various vision tasks; A booster module to raise the performance of pretrained backbones; A highly efficient fine-tuning module that adapts the base model for transfer learning tasks. Extensive experiments verify the effectiveness of Mamba-Adapter in three settings. Notably, our Mamba-Adapter achieves state-of-the-art on the ImageNet and COCO benchmarks. The code will be released publicly.