RADIOv2.5: Improved Baselines for Agglomerative Vision Foundation Models
{kind=link}
Abstract
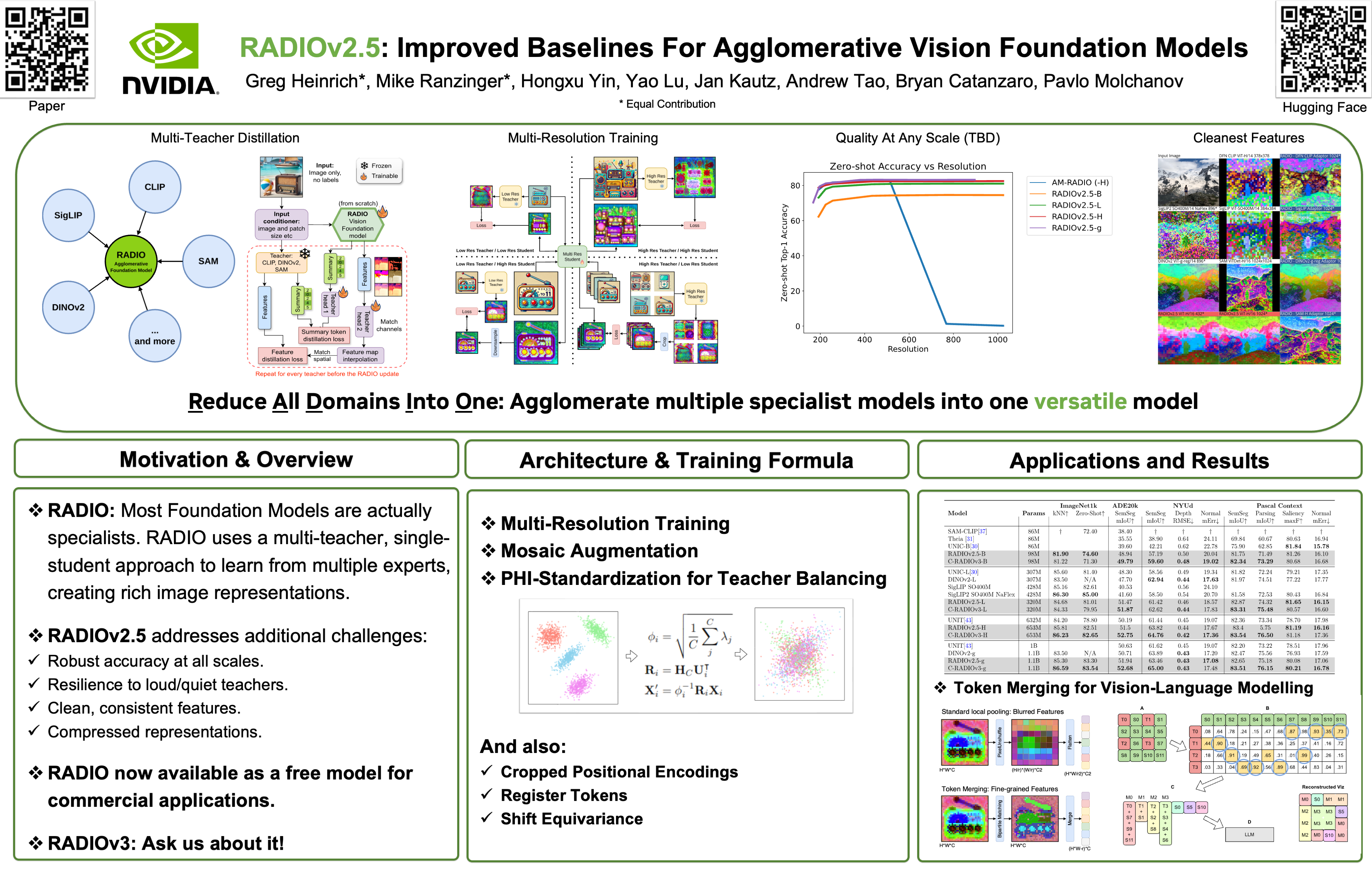
Agglomerative models have recently emerged as a powerful approach to training vision foundation models, leveraging multi-teacher distillation from existing models such as CLIP, DINO, and SAM. This strategy enables the creation of robust models more efficiently, combining the strengths of individual teachers while significantly reducing computational and resource demands. In this paper, we thoroughly analyze state-of-the-art agglomerative models, identifying critical challenges including resolution mode shifts, teacher imbalance, weak initializations, idiosyncratic teacher artifacts, and an excessive number of output tokens. To address these issues, we propose several novel solutions: multi-resolution training, mosaic augmentation, and improved balancing of teacher loss functions. Specifically, in the context of Vision Language Models, we introduce a token compression technique to maintain high-resolution information within a fixed token count. We release our top-performing models, available in multiple scales (-B, -L, and -H), alongside code and pretrained weights, to support further research and development in the community.