MVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation
{kind=link}
Abstract
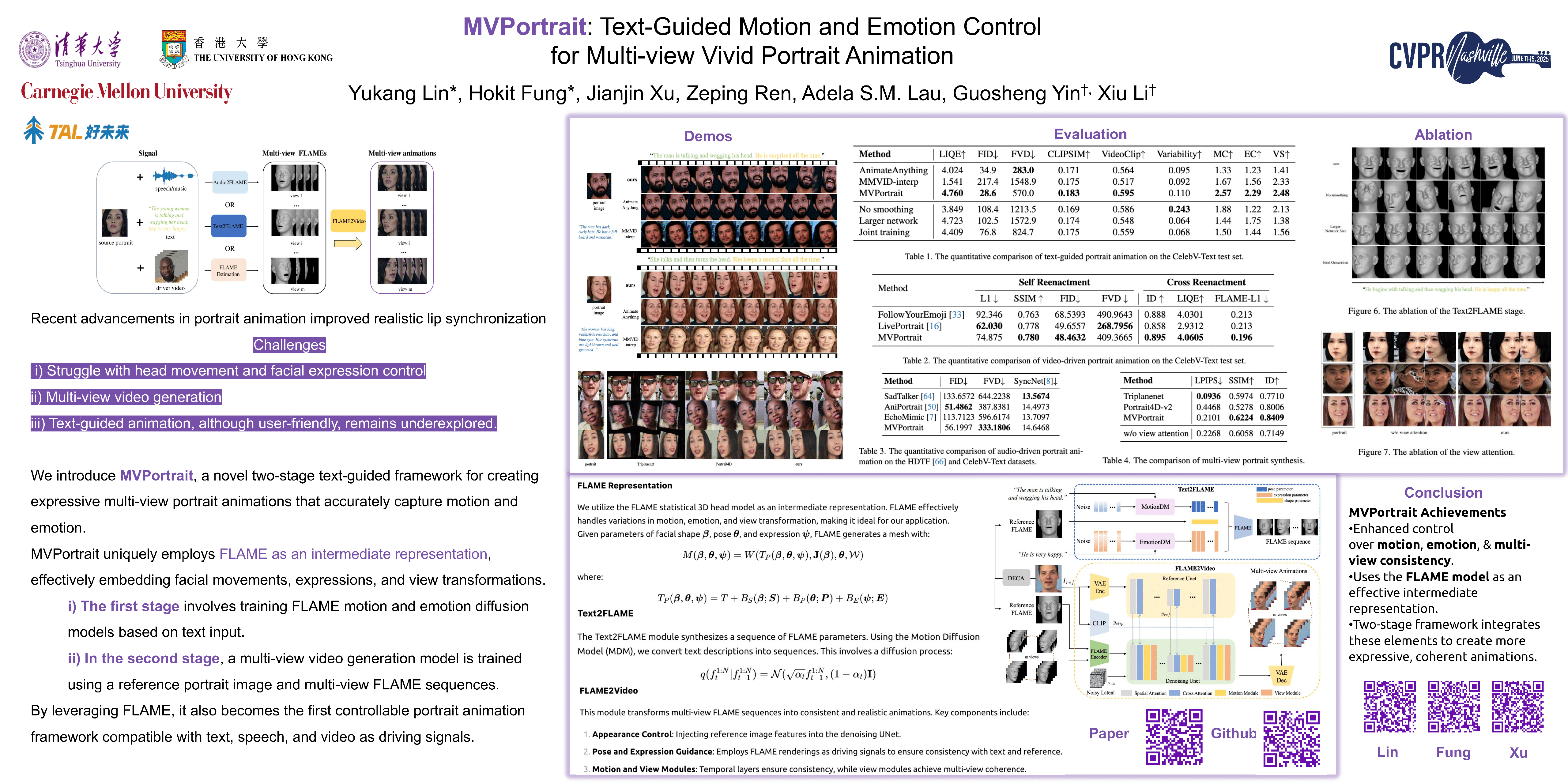
Recent portrait animation methods have made significant strides in generating realistic lip synchronization. However, they often lack explicit control over head movements and facial expressions, and cannot produce videos from multiple viewpoints, resulting in less controllable and expressive animations. Moreover, text-guided portrait animation remains underexplored, despite its user-friendly nature. In this paper, we present a novel two-stage text-guided framework, MVPortrait, to generate expressive multi-view portrait animations that faithfully capture the described motion and emotion. MVPortrait is the first to introduce FLAME as an intermediate representation, effectively embedding facial movements, expressions, and view transformations within its parameter space. In the first stage, we separately train the FLAME motion and emotion diffusion models based on text input. In the second stage, we train a multi-view video generation model conditioned on a reference portrait image and multi-view FLAME rendering sequences from the first stage. Experimental results exhibit that MVPortrait outperforms existing methods in terms of motion and emotion control, as well as view consistency. Furthermore, by leveraging FLAME as a bridge, MVPortrait becomes the first controllable portrait animation framework that is compatible with text, speech, and video as driving signals.