MEET: Towards Memory-Efficient Temporal Sparse Deep Neural Networks
Zeqi Zhu ⋅ Ibrahim Batuhan Akkaya ⋅ Luc Waeijen ⋅ Egor Bondarev ⋅ Arash Pourtaherian ⋅ Orlando Moreira
2025 Poster
{kind=link}
Abstract
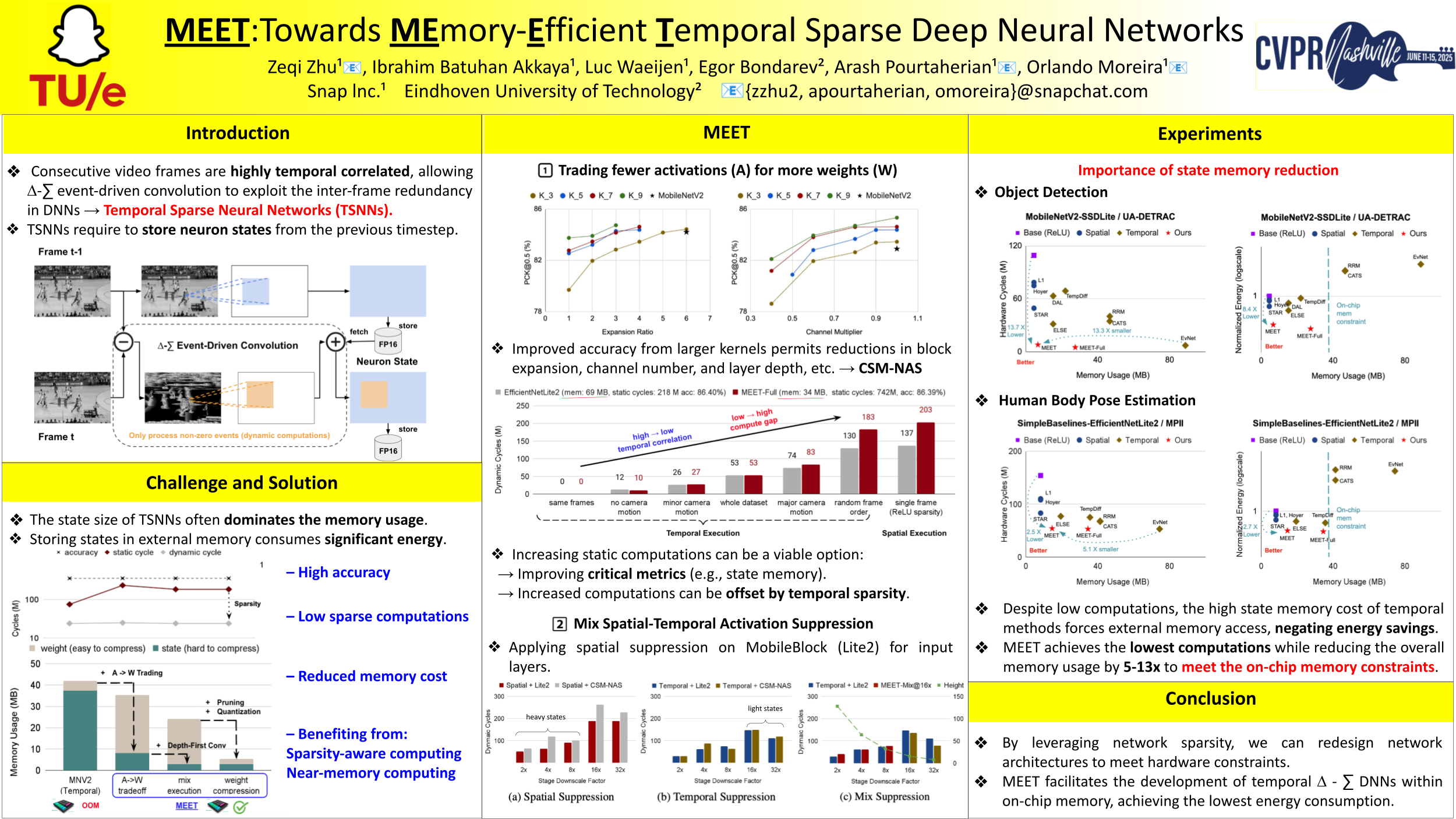
Deep Neural Networks (DNNs) are accurate but compute-intensive, leading to substantial energy consumption during inference. Exploiting temporal redundancy through $\Delta$-$\Sigma$ convolution in video processing has proven to greatly enhance computation efficiency. However, temporal $\Delta$-$\Sigma$ DNNs typically require substantial memory for storing neuron states to compute inter-frame differences, hindering their on-chip deployment. To mitigate this memory cost, directly compressing the states can disrupt the linearity of temporal $\Delta$-$\Sigma$ convolution, causing accumulated errors in long-term $\Delta$-$\Sigma$ processing. Thus, we propose $\textbf{MEET}$, an optimization framework for $\textbf{ME}$mory-$\textbf{E}$fficient $\textbf{T}$emporal $\Delta$-$\Sigma$ DNNs. MEET transfers the state compression challenge to a well-established weight compression problem by trading fewer activations for more weights and introduces a co-design of network architecture and suppression method to optimize for mixed spatial-temporal execution. Evaluations on three vision applications demonstrate a reduction of 5.1$\sim$13.3 $\times$ in total memory compared to the most computation-efficient temporal DNNs, while preserving the computation efficiency and model accuracy in long-term $\Delta$-$\Sigma$ processing. MEET facilitates the deployment of temporal $\Delta$-$\Sigma$ DNNs within on-chip memory of embedded event-driven platforms, empowering low-power edge processing.
Chat is not available.
Successful Page Load