Adventurer: Optimizing Vision Mamba Architecture Designs for Efficiency
{kind=link}
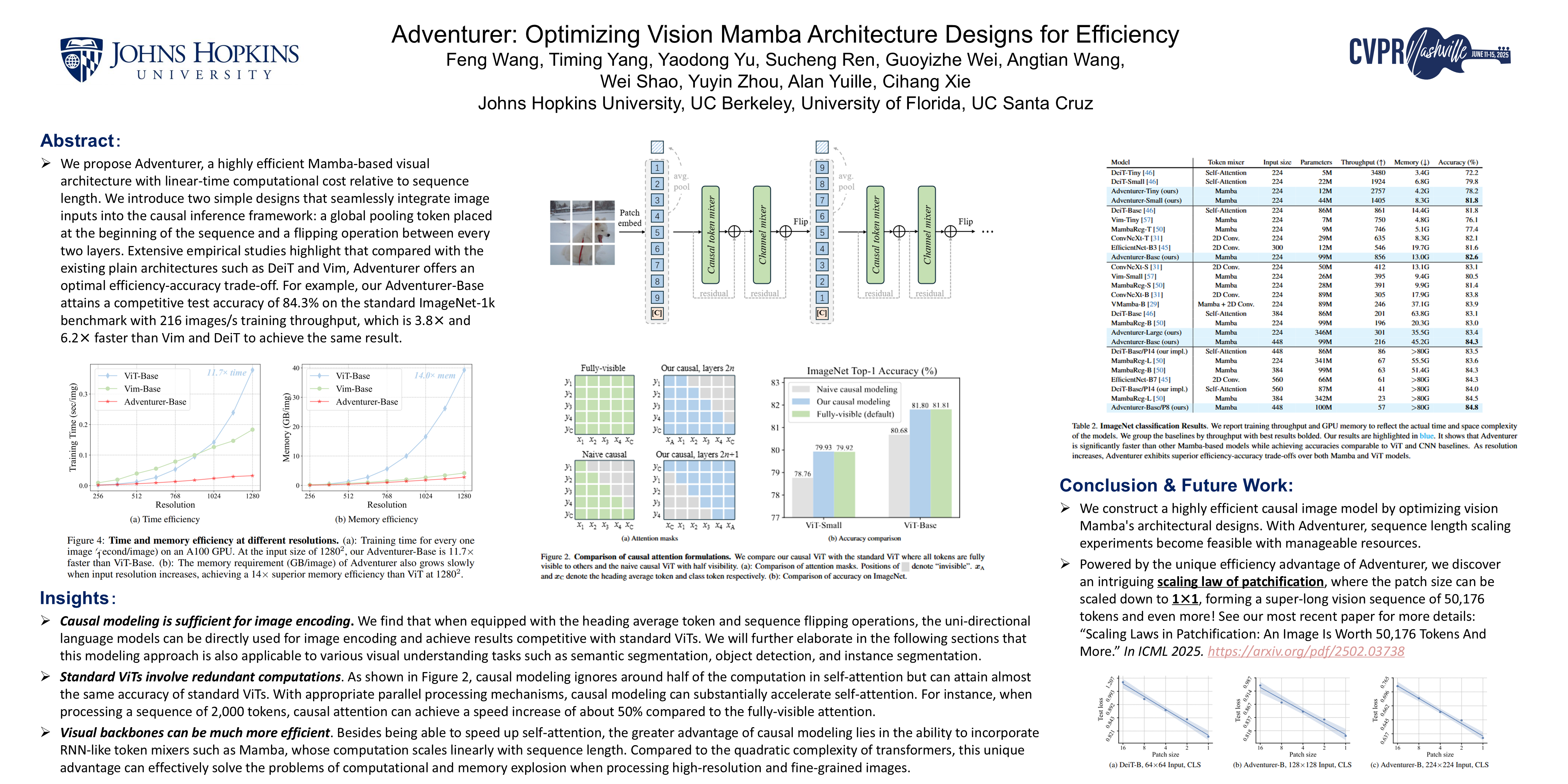
Abstract
In this work, we introduce the Adventurer series models where we treat images as sequences of patch tokens and employ uni-directional language models to learn visual representations. This modeling paradigm allows us to process images in a recurrent formulation with linear complexity relative to the sequence length, which can effectively address the memory and computation explosion issues posed by high-resolution and fine-grained images. In detail, we introduce two simple designs that seamlessly integrate image inputs into the causal inference framework: a global pooling token placed at the beginning of the sequence and a flipping operation between every two layers. Extensive empirical studies highlight that compared with the existing plain architectures such as DeiT and Vim, Adventurer offers an optimal efficiency-accuracy trade-off. For example, our Adventurer-Base attains a competitive test accuracy of 84.3% on the standard ImageNet-1k benchmark with 216 images/s training throughput, which is 3.8x and 6.2x faster than Vim and DeiT to achieve the same result. As Adventurer offers great computation and memory efficiency and allows scaling with linear complexity, we hope this architecture can benefit future explorations in modeling long sequences for high-resolution or fine-grained images.