LongDiff: Training-Free Long Video Generation in One Go
{kind=link}
Abstract
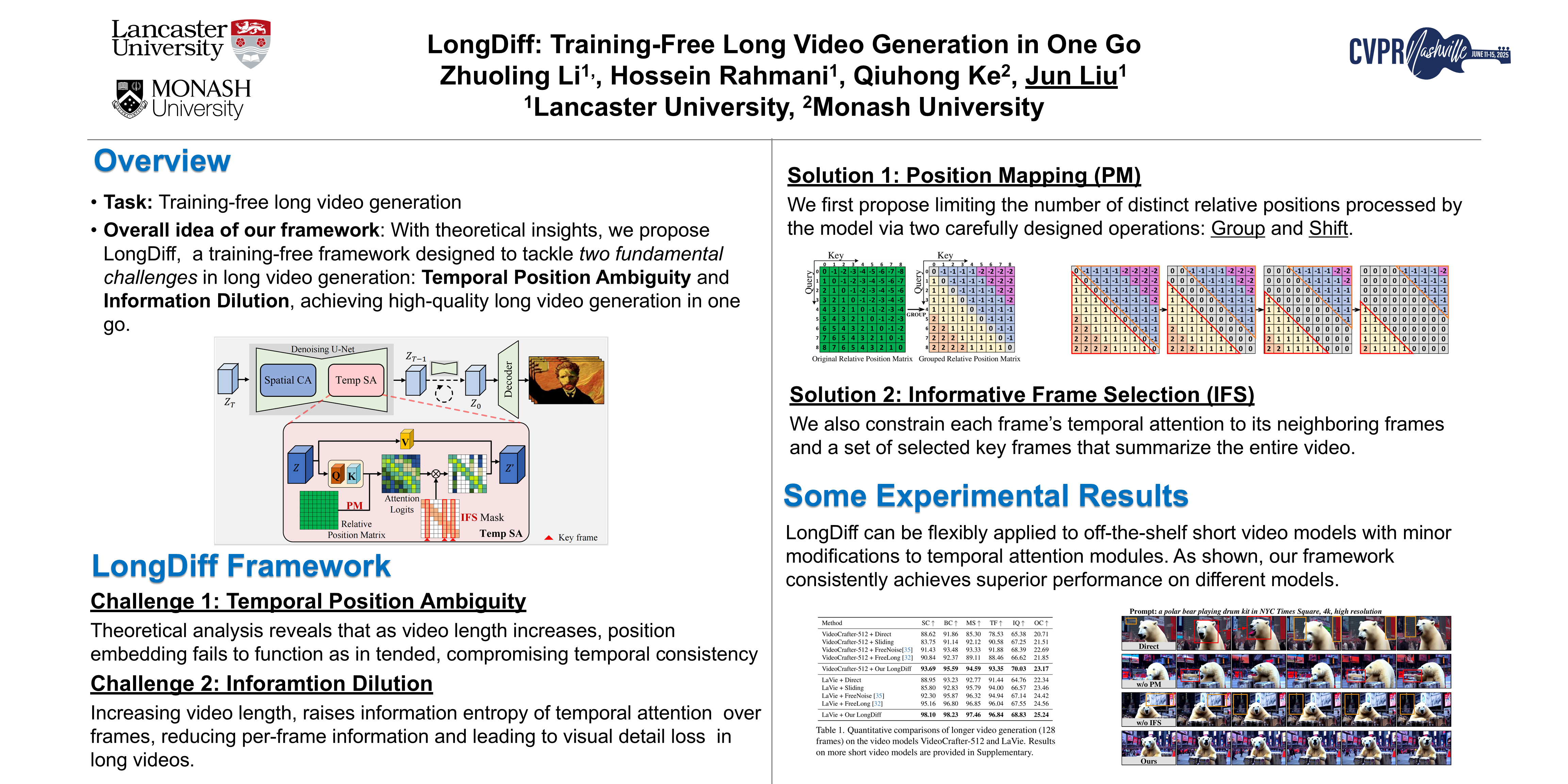
Video diffusion models have recently achieved remarkable results in video generation. Despite their encouraging performance, most of these models are mainly designed and trained for short video generation, leading to challenges in maintaining temporal consistency and visual details in long video generation. In this paper, through theoretical analysis of the mechanisms behind video generation, we identify two key challenges that hinder short-to-long generalization, namely, temporal position ambiguity and information dilution. To address these challenges, we propose LongDiff, a novel training-free method that unlocks the potential of the off-the-shelf video diffusion models to achieve high-quality long video generation in one go. Extensive experiments demonstrate the efficacy of our method.