Towards Precise Embodied Dialogue Localization via Causality Guided Diffusion
{kind=link}
Abstract
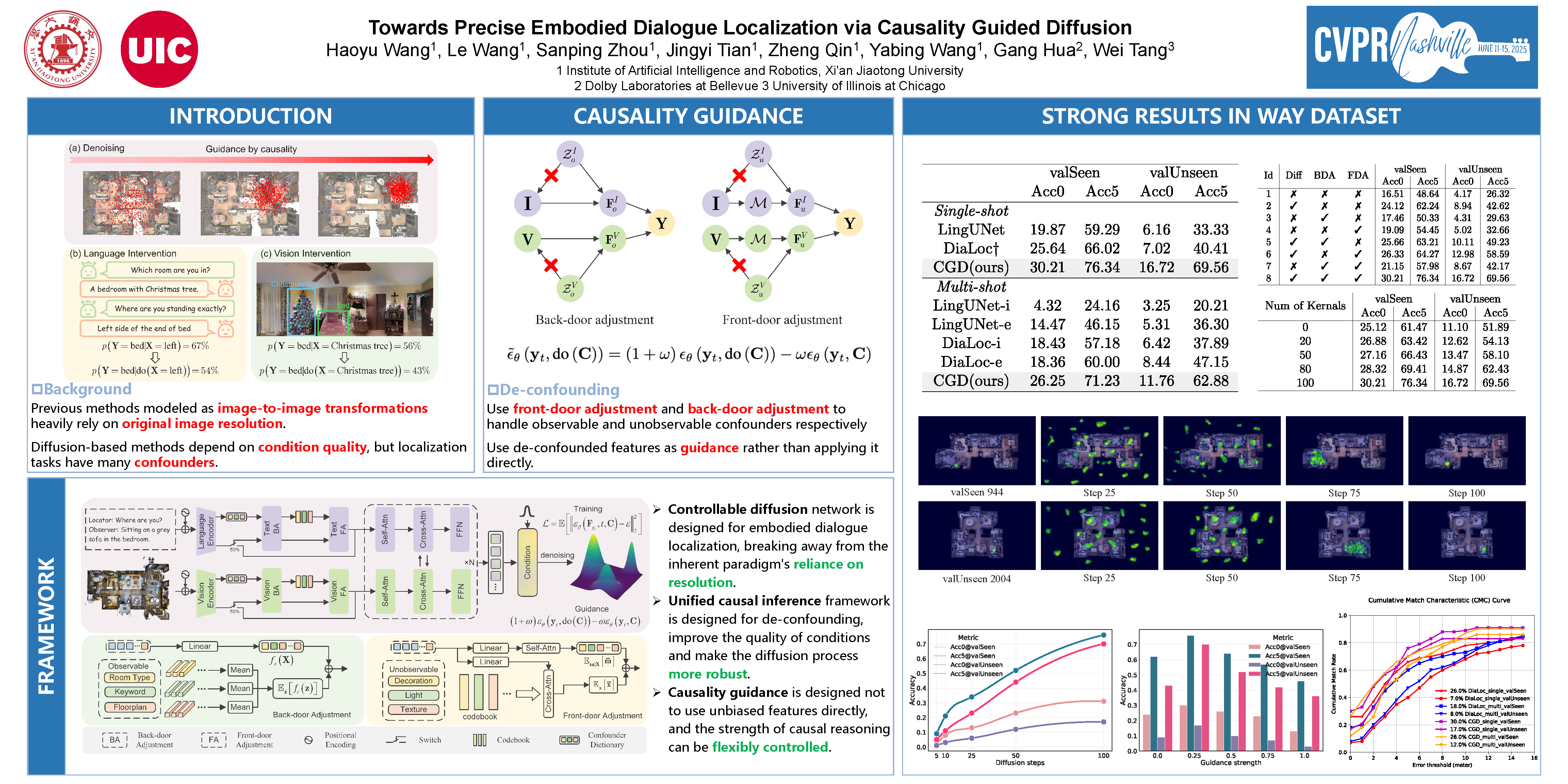
Embodied localization based on vision and natural language dialogues presents a persistent challenge in embodied intelligence. Existing methods often approach this task as an image translation problem, leveraging encoder-decoder architectures to predict heatmaps. However, these methods frequently experience a deficiency in accuracy, largely due to their heavy reliance on resolution. To address this issue, we introduce CGD, a novel framework that utilizes causality guided diffusion model to directly model coordinate distributions. Specifically, CGD employs a denoising network to regress coordinates, while integrating causal learning modules, namely back-door adjustment (BDA) and front-door adjustment (FDA) to mitigate confounders during the diffusion process. This approach reduces the dependency on high resolution for improving accuracy, while effectively minimizing spurious correlations, thereby promoting unbiased learning. By guiding the denoising process with causal adjustments, CGD offers flexible control over intensity, ensuring seamless integration with diffusion models. Experimental results demonstrate that CGD outperforms state-of-the-art methods across all metrics. Additionally, we also evaluate CGD in a multi-shot setting, achieving consistently high accuracy.