Dual Semantic Guidance for Open Vocabulary Semantic Segmentation
{kind=link}
Abstract
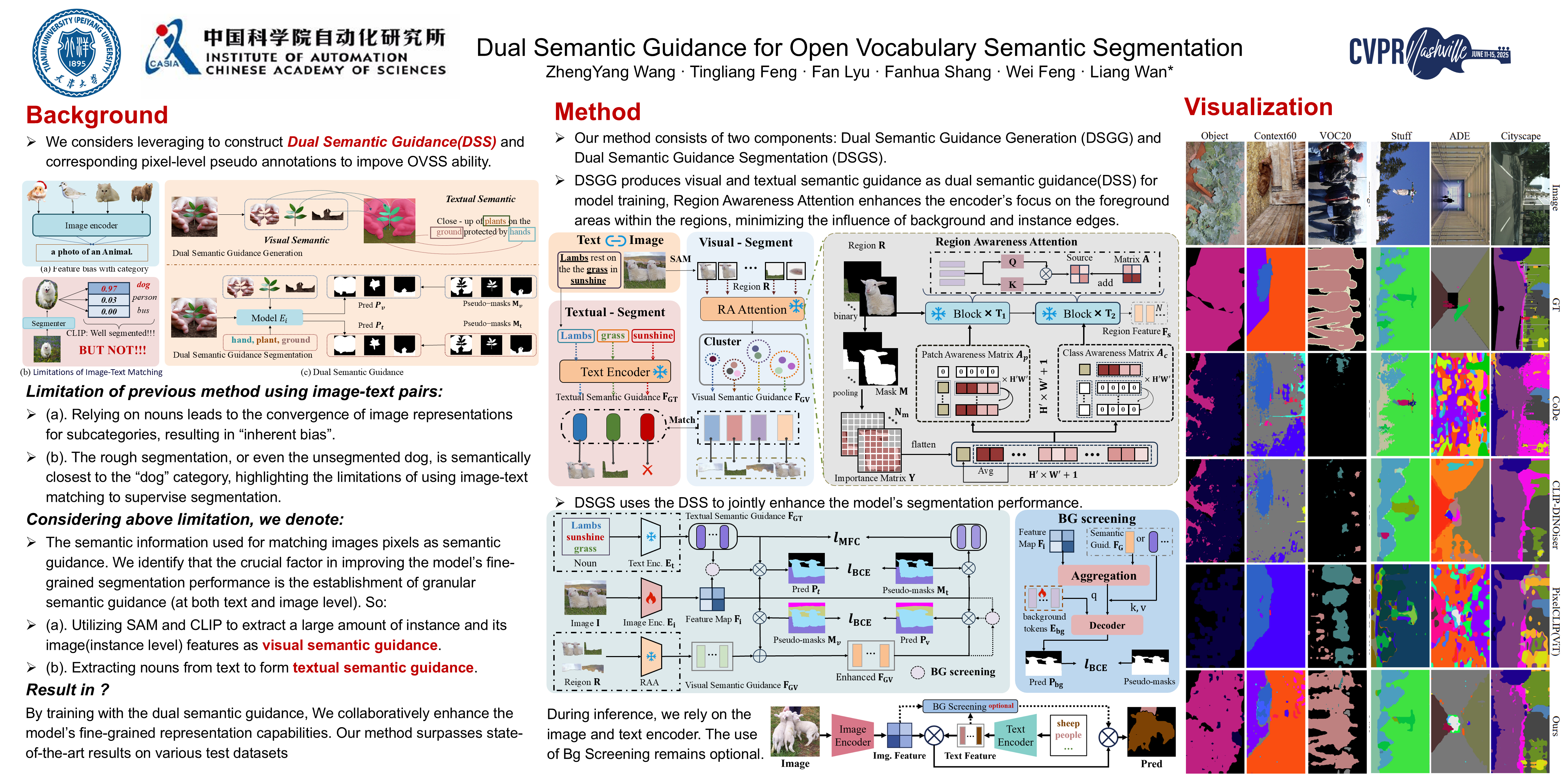
Open-vocabulary semantic segmentation aims to enable models to segment arbitrary categories. Currently, though pre-trained Vision-Language Models (VLMs) like CLIP have established a robust foundation for this task by learning to match text and image representations from large-scale data, their lack of pixel-level recognition necessitates further fine-tuning. Most existing methods leverage text as a guide to achieve pixel-level recognition. However, the inherent biases in text semantic descriptions and the lack of pixel-level supervisory information make it challenging to fine-tune CLIP-based models effectively. This paper considers leveraging image-text data to simultaneously capture the semantic information contained in both image and text, thereby constructing Dual Semantic Guidance and corresponding pixel-level pseudo annotations. Particularly, the visual semantic guidance is enhanced via explicitly exploring foreground regions and minimizing the influence of background. The dual semantic guidance is then jointly utilized to fine-tune CLIP-based segmentation models, achieving decent fine-grained recognition capabilities. As the comprehensive evaluation shows, our method outperforms state-of-art results with large margins, on eight commonly used datasets with/without background.