Font-Agent: Enhancing Font Understanding with Large Language Models
{kind=link}
Abstract
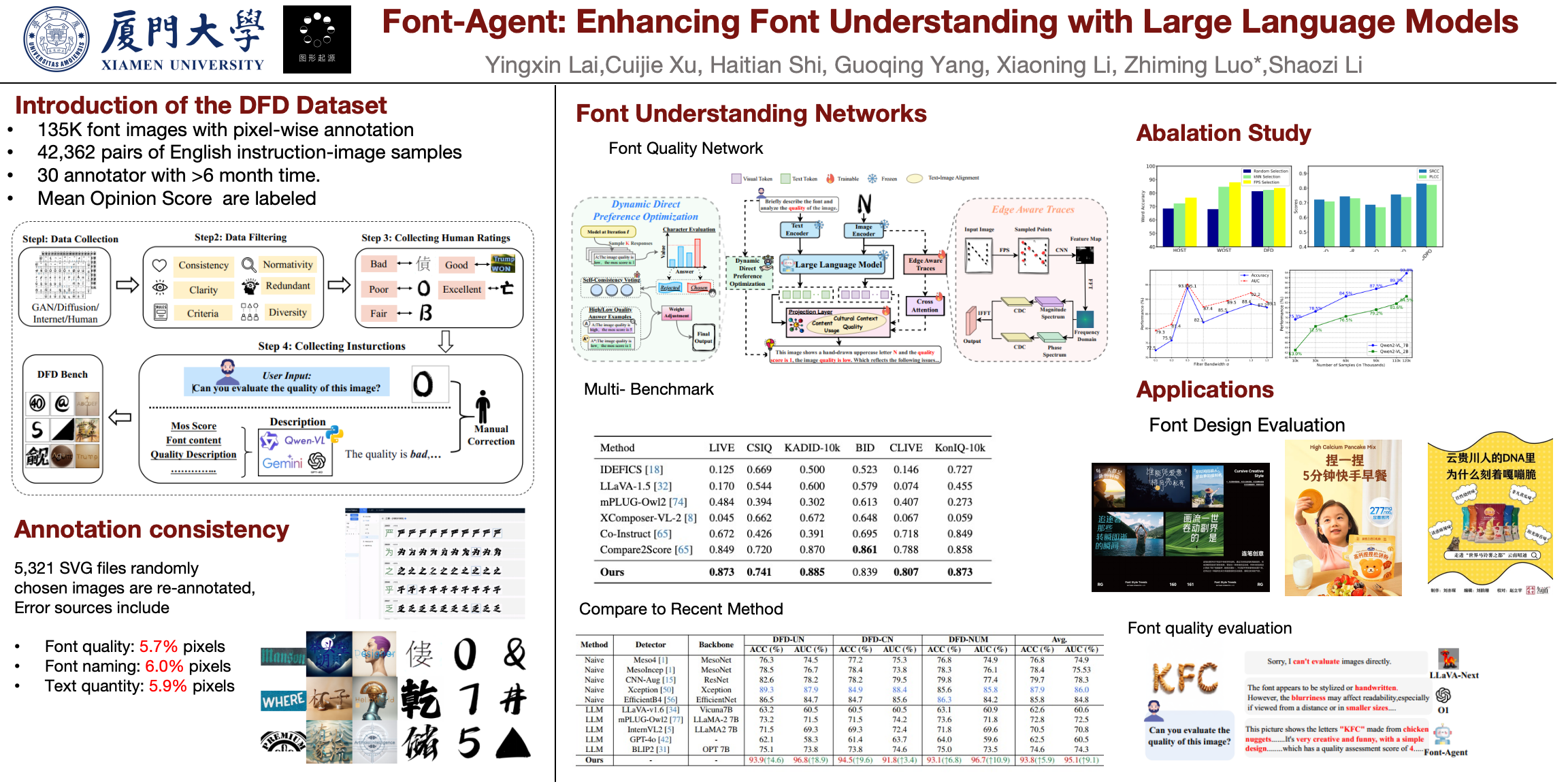
The rapid development of generative models has significantly advanced the font generation. However, limited explorations have been devoted into the evaluation and interpretability of graphical fonts. Especially, existing quality assessment models can only provide basic visual capabilities, such as recognizing clarity and brightness, lacking in-depth explanation.To address these limitations, we firstly constructed a large-scale multimodal dataset comprising 135,000 font-text pairs named Diversity Font Dataset (DFD). This dataset includes a wide range of generated font types and annotations including language descriptions and quality assessments, providing a strong basis for training and evaluating font analysis models.Based on the dataset, we developed a Vision Language Model (VLM)-based Font-Agent with the aim of improving font quality assessment and offering interpretative question-answering capabilities. Alongside the original visual encoder in VLM, we integrated a Edge Aware Traces (EAT) Module to capture detailed edge information of font strokes and components. Furthermore, we introduce a Dynamic Direct Preference Optimization (D-DPO) strategy to facilitate efficient model fine-tuning. Experimental outcomes showcase that Font-Agent achieves state-of-the-art performance on the the established dataset. To further assess the generalization of our algorithm, we conducted evaluation on several public datasets. The results highlight the notable advantage of Font-Agent in both assessing the quality of generated fonts and comprehending their contents.