Disentangled Pose and Appearance Guidance for Multi-Pose Generation
{kind=link}
Abstract
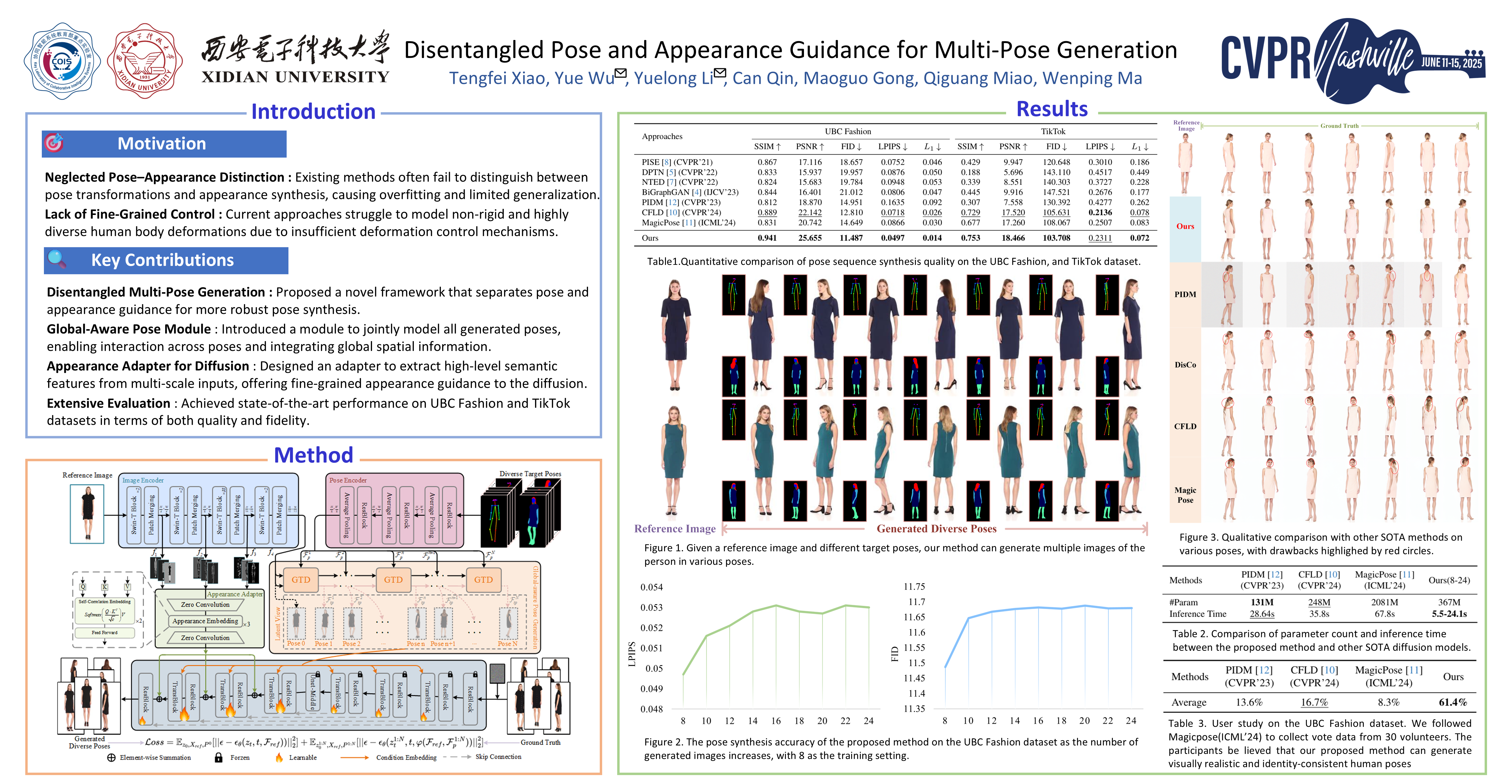
Human pose generation is a complex task due to the non-rigid and highly variable nature of human body structures and appearances. While existing methods overlook the fundamental differences between spatial transformations of poses and texture generation for appearance, making them prone to overfitting. To this end, a multi-pose generation framework is proposed which is driven by disentangled pose and appearance guidance. Our approach comprises a Global-aware Pose Generation module that iteratively generates pose embeddings, enabling effective control over non-rigid body deformations. Additionally, we introduce the Global-aware Transformer Decoder, which leverages similarity queries and attention mechanisms to achieve spatial transformations and enhance pose consistency through a Global-aware block. In the appearance generation phase, we condition a diffusion model on pose embeddings produced in the initial stage and introduce an appearance adapter that extracts high-level contextual semantic information from multi-scale features, enabling further refinement of pose appearance textures and providing appearance guidance. Extensive experiments on the UBC Fashion and TikTok datasets demonstrate that our framework achieves state-of-the-art results in both quality and fidelity, establishing it as a powerful approach for complex pose generation tasks.