TAGA: Self-supervised Learning for Template-free Animatable Gaussian Articulated Model
{kind=link}
Abstract
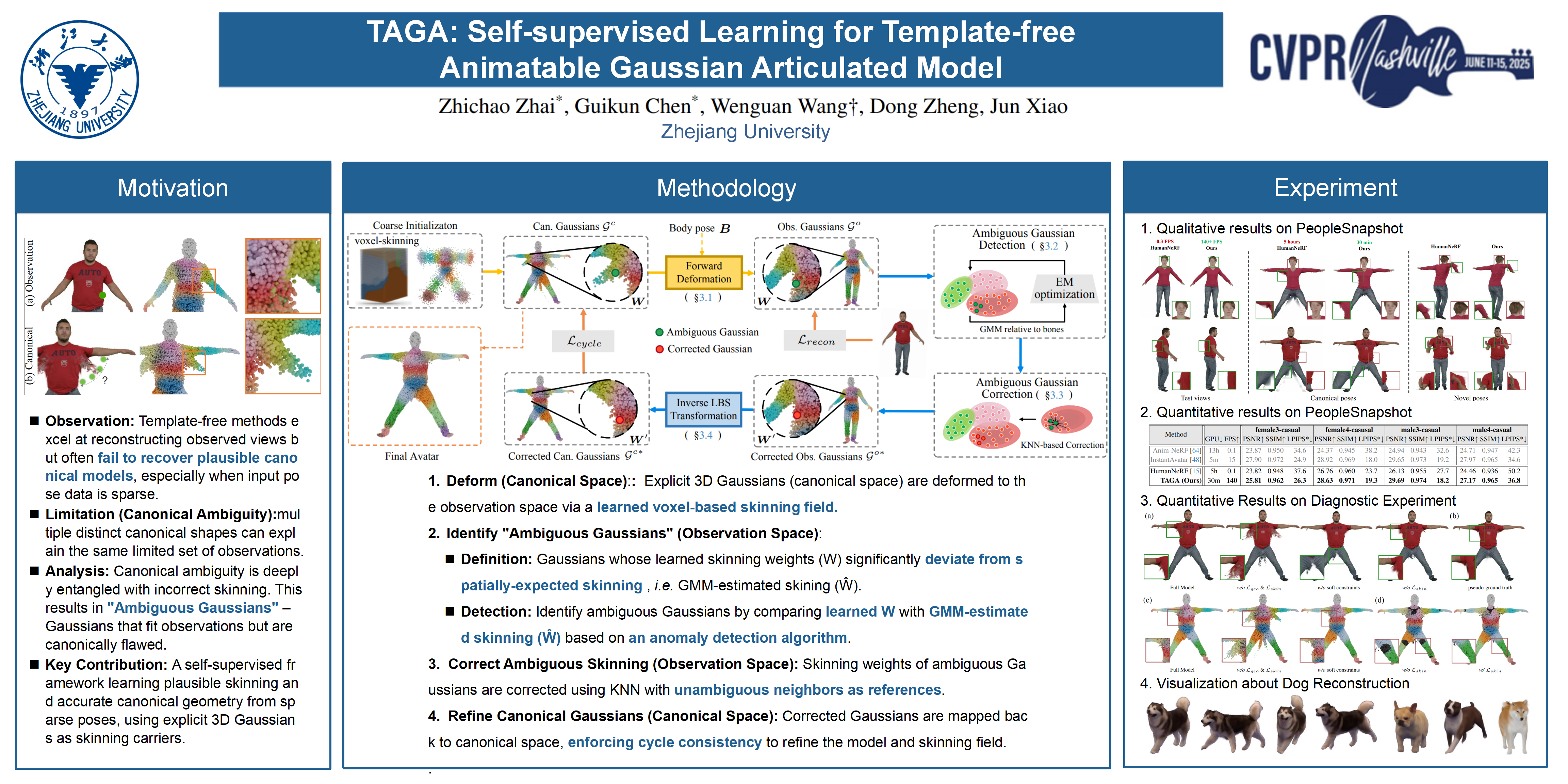
Decoupling from customized parametric templates represents a crucial step toward the creation of fully flexible, animatable articulated models. While existing template-free methods can achieve high-fidelity reconstruction in observed views, they struggle to recover plausible canonical models, resulting in suboptimal animation quality. This limitation stems from overlooking the fundamental ambiguities in canonical reconstruction, where multiple canonical models could explain the same observed views. This work reveals the entanglement between canonical ambiguities and incorrect skinning, and presents a self-supervised framework that learns both plausible skinning and accurate canonical geometry using only sparse pose data. Our method, TAGA, uses explicit 3D Gaussians as skinning carriers and characterizes ambiguities as "Ambiguous Gaussians" with incorrect skinning weights. TAGA then corrects ambiguous Gaussians in the observation space using anomaly detection. With the corrected ones, we enforce cycle consistency constraints on both geometry and skinning to refine the corresponding Gaussians in the canonical space through a new backward method. Compared to existing state-of-the-art template-free methods, TAGA delivers superior visual fidelity for novel views and poses, while significantly improving training and rendering speeds. Experiments on challenging datasets with limited pose variations further demonstrate the robustness and generality of TAGA. The code will be released.