SOAP: Vision-Centric 3D Semantic Scene Completion with Scene-Adaptive Decoder and Occluded Region-Aware View Projection
{kind=link}
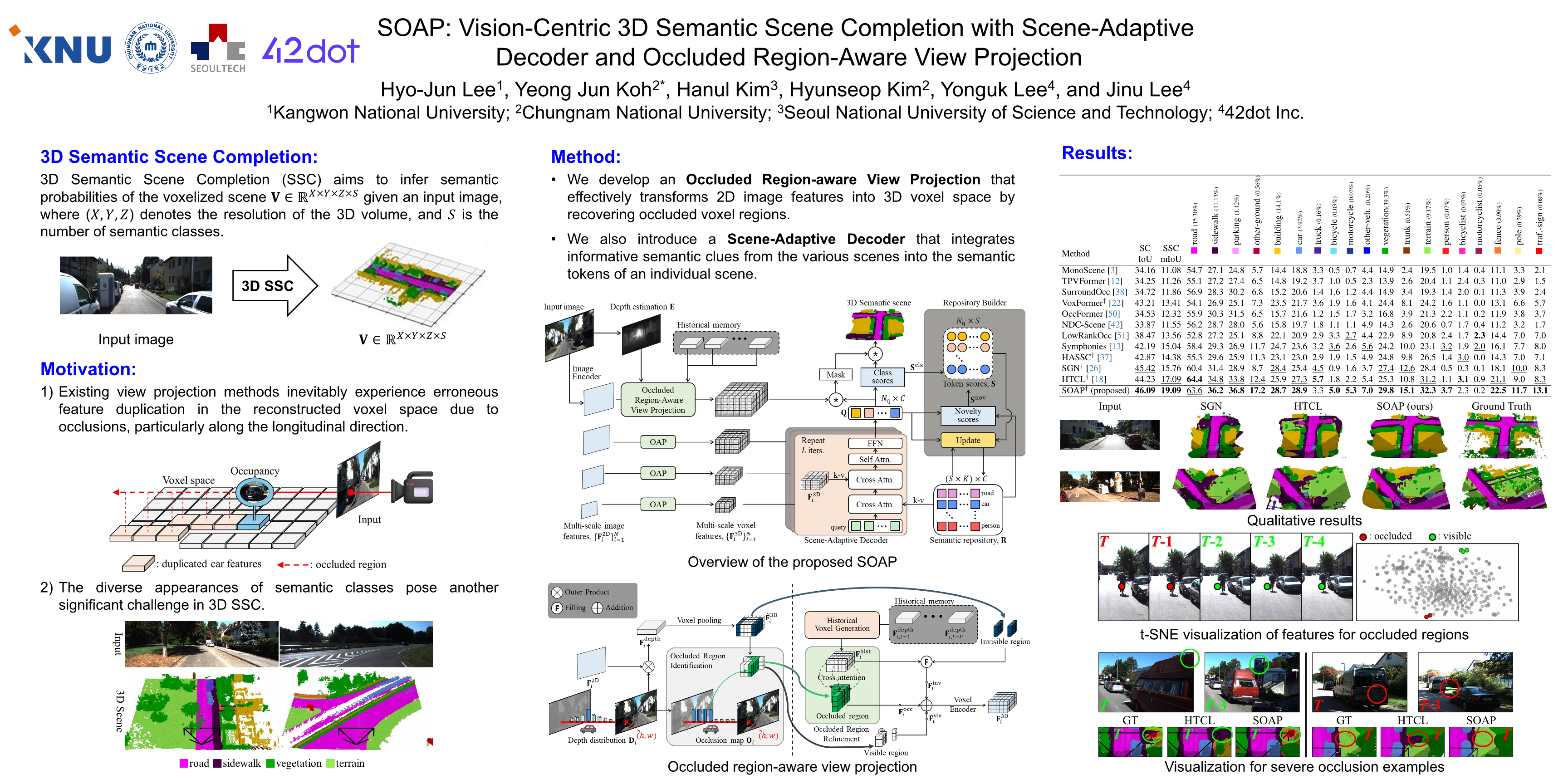
Abstract
Vision-centric 3D Semantic Scene Completion (SSC) aims to reconstruct a fine-grained 3D scene from an input RGB image. Since the vision-centric 3D SSC is an ill-posed problem, it requires a precise 2D-3D view transformation. However, existing view transformations inevitably experience erroneous feature duplication in the reconstructed voxel space due to occlusions, leading to a dilution of informative contexts. Furthermore, semantic classes exhibit high variability in their appearance in real-world driving scenarios. To address these issues, we introduce a novel 3D SSC method, called SOAP, including two key components: an occluded region-aware view projection and a scene-adaptive decoder. The occluded region-aware view projection effectively converts 2D image features into voxel space, refining the duplicated features of occluded regions using information gathered from previous observations. The scene-adaptive decoder guides query embeddings to learn diverse driving environments based on a comprehensive semantic repository. Extensive experiments validate that the proposed SOAP significantly outperforms existing methods for the vision-centric 3D SSC on automated driving datasets, SemanticKITTI and SSCBench.