It’s a (Blind) Match! Towards Vision-Language Correspondence without Parallel Data
{kind=link}
Abstract
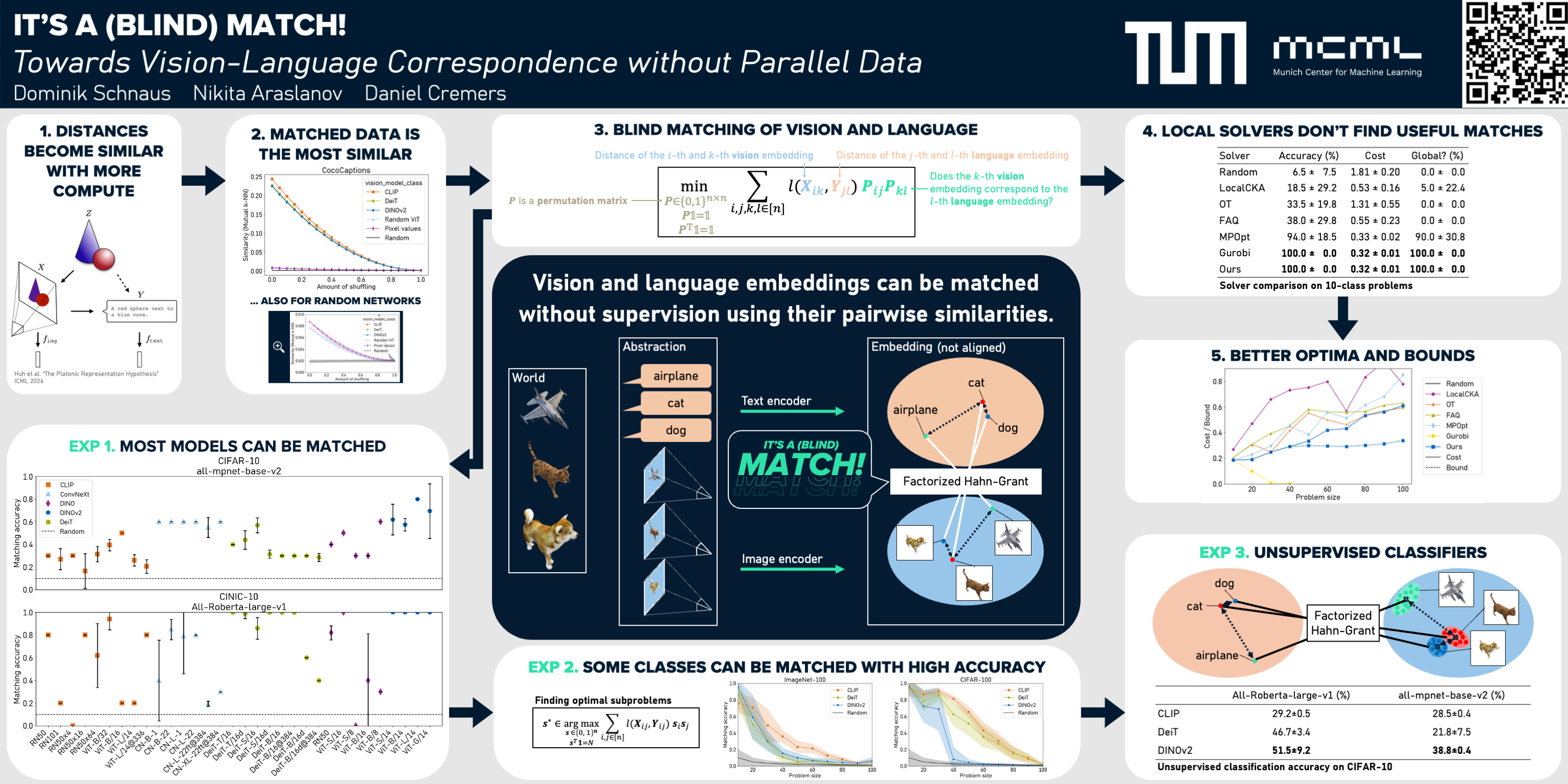
The platonic representation hypothesis suggests that vision and language embeddings become more homogeneous as model and dataset sizes increase. In particular, pairwise distances within each modality become more similar. This suggests that as foundation models mature, it may become possible to match vision and language embeddings in a fully unsupervised fashion, i.e., without parallel data. We present the first study towards this prospect, and investigate conformity of existing vision and language foundation models in the context of "blind" matching. First, we formulate unsupervised matching as a quadratic assignment problem and introduce a novel heuristic that outperforms previous solvers. We also develop a technique to find optimal matching problems, for which a non-trivial match is very likely. Second, we conduct an extensive study deploying a range of vision and language models on four datasets. Our analysis reveals that for many problem instances, vision and language representations can be indeed matched without supervision. This finding opens possibility for exciting applications embedding semantic knowledge into other modalities. As a showcase, we demonstrate a proof-of-concept unsupervised classifier, which achieves non-trivial classification accuracy without any image-text annotation.