Adaptive Parameter Selection for Tuning Vision-Language Models
{kind=link}
Abstract
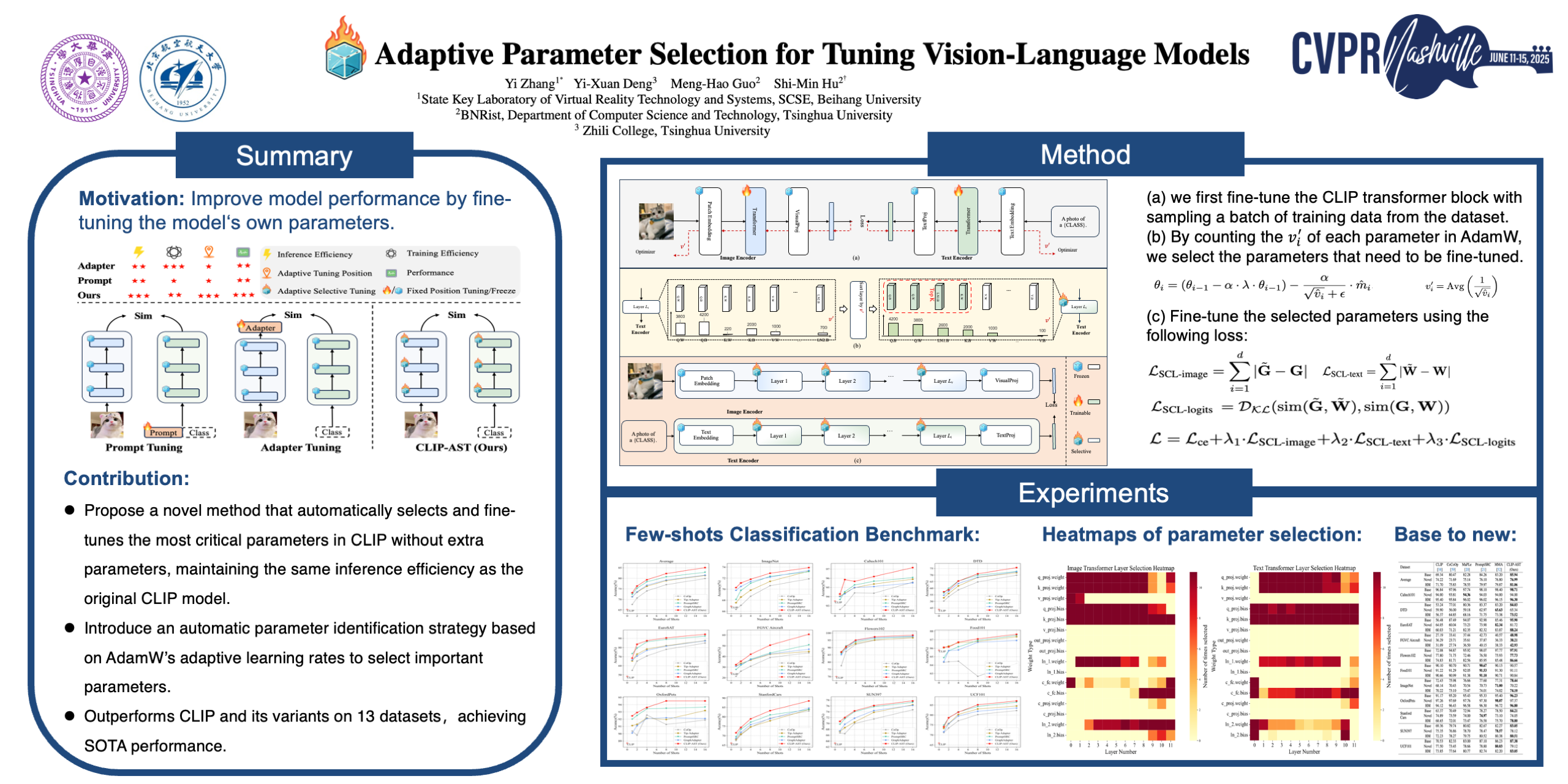
Vision-language models (VLMs) like CLIP have been widely used in various specific tasks.Parameter-efficient fine-tuning (PEFT) methods, such as prompt and adapter tuning,have become key techniques for adapting these models to specific domains.However, existing approaches rely on prior knowledgeto manually identify the locations requiring fine-tuning.Adaptively selecting which parameters in VLMs should be tuned remains unexplored. In this paper, we propose CLIP with Adaptive Selective Tuning (CLIP-AST), which can be used to automatically select critical parameters in VLMs for fine-tuning for specific tasks.It opportunely leveragesthe adaptive learning rate in the optimizer and improves model performance without extra parameter overhead. We conduct extensive experiments on 13 benchmarks, such as ImageNet, Food101, Flowers102, etc,with different settings, including few-shot learning, base-to-novel class generalization, and out-of-distribution. The results show that CLIP-AST consistently outperforms the original CLIP model as well as its variantsand achieves state-of-the-art (SOTA) performance in all cases. For example, with the 16-shot learning, CLIP-AST surpasses GraphAdapter and PromptSRC by 3.56\% and 2.20\% in average accuracy on 11 datasets, respectively.Code will be publicly available.