Robust-MVTON: Learning Cross-Pose Feature Alignment and Fusion for Robust Multi-View Virtual Try-On
{kind=link}
Abstract
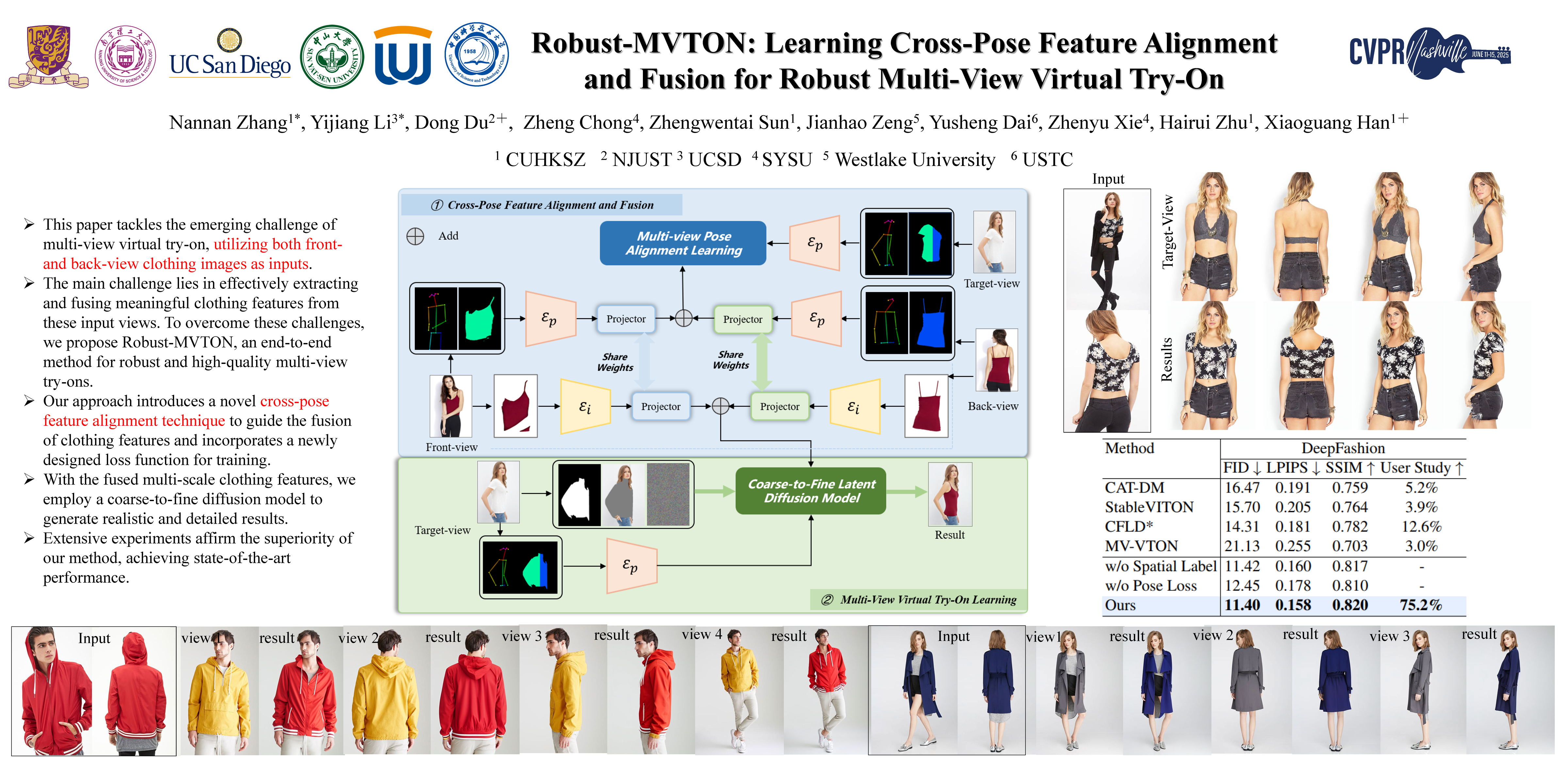
This paper tackles the emerging challenge of multi-view virtual try-on, utilizing both front- and back-view clothing images as inputs. Extending frontal try-on methods to a multi-view context is not straightforward. Simply concatenating the two input views or encoding their features for a generative model, such as a diffusion model, often fails to produce satisfactory results. The main challenge lies in effectively extracting and fusing meaningful clothing features from these input views. Existing explicit warping-based methods, which establish direct correspondence between input and target views, tend to introduce artifacts, particularly when there is a significant disparity between the input and target views. Conversely, implicit encoding-based methods often lose spatial information about clothing, resulting in outputs that lack detail. To overcome these challenges, we propose Robust-MVTON, an end-to-end method for robust and high-quality multi-view try-ons. Our approach introduces a novel cross-pose feature alignment technique to guide the fusion of clothing features and incorporates a newly designed loss function for training. With the fused multi-scale clothing features, we employ a coarse-to-fine diffusion model to generate realistic and detailed results. Extensive experiments conducted on the Deepfashion and MPV datasets affirm the superiority of our method, achieving state-of-the-art performance.