Dynamic Content Prediction with Motion-aware Priors for Blind Face Video Restoration
{kind=link}
Abstract
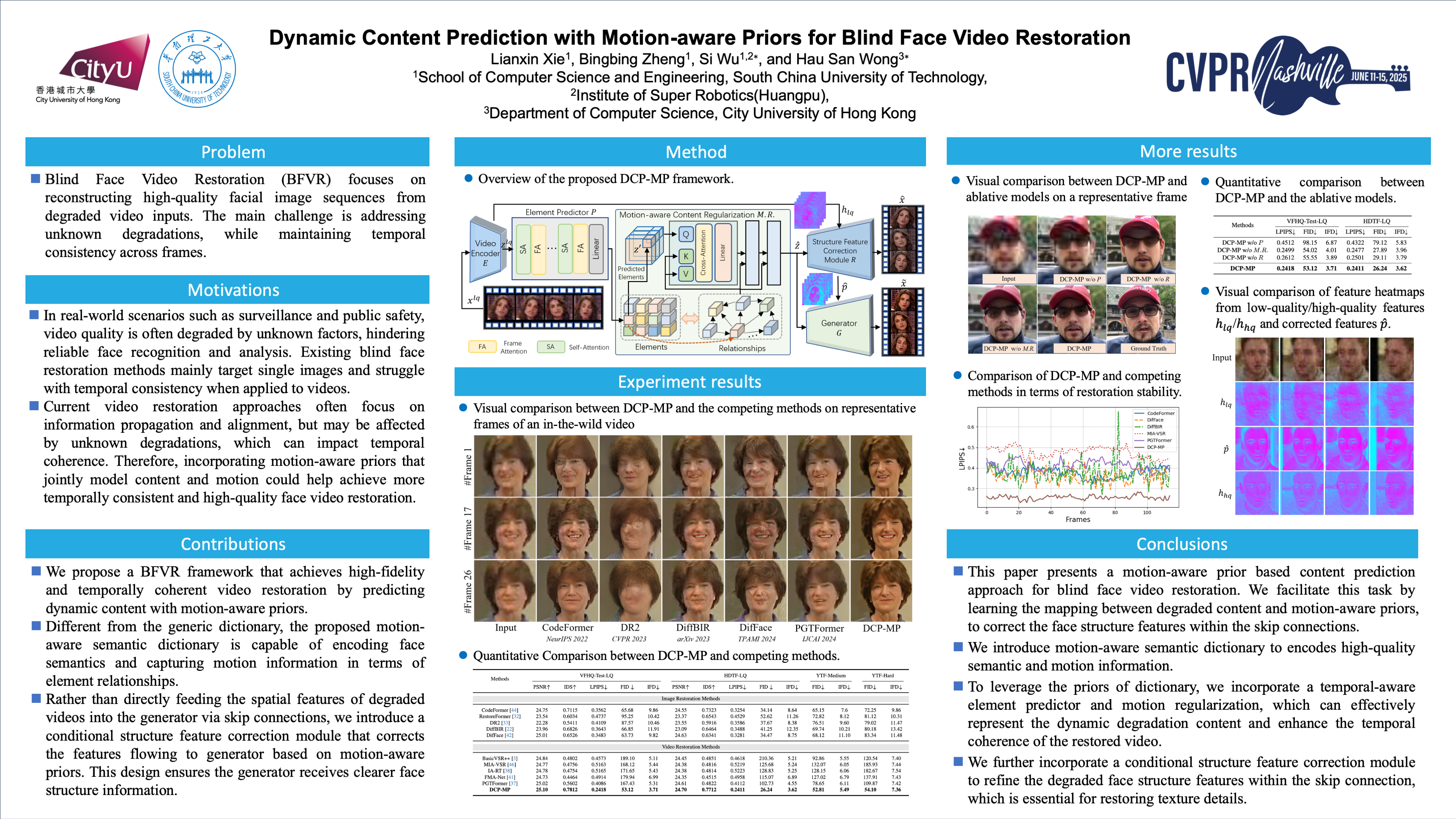
Blind Face Video Restoration (BFVR) focuses on reconstructing high-quality facial image sequences from degraded video inputs. The main challenge is address unknown degradations, while maintaining temporal consistency across frames. Current blind face restoration methods are primarily designed for images, and directly applying these approaches to BFVR will encounter a significant drop in restoration performance. In this work, we proposed Dynamic Content Prediction with Motion-aware Priors, referred to as DCP-MP. We develop a motion-aware semantic dictionary by encoding the semantic information of high-quality videos into discrete elements, and capturing the motion information in terms of element relationships, which are derived from the dynamic temporal changes within videos. For the purpose of utilizing dictionary to represent the degraded video, we train a temporal-aware element predictor, conditioned on degraded content, to learn the prediction of discrete elements in dictionary. The predicted elements will be refined, conditioned on motion information captured by the motion-aware semantic dictionary, to enhance temporal coherence. To alleviate deviation from the original structure information, we propose a conditional structure feature correction module that corrects the features flowing from the encoder to the generator. Through extensive experiments, we validate the effectiveness of our design components and demonstrate the superior performance of DCP-MP in synthesizing high-quality video.