L-SWAG: Layer-Sample Wise Activation with Gradients Information for Zero-Shot NAS on Vision Transformers
{kind=link}
Abstract
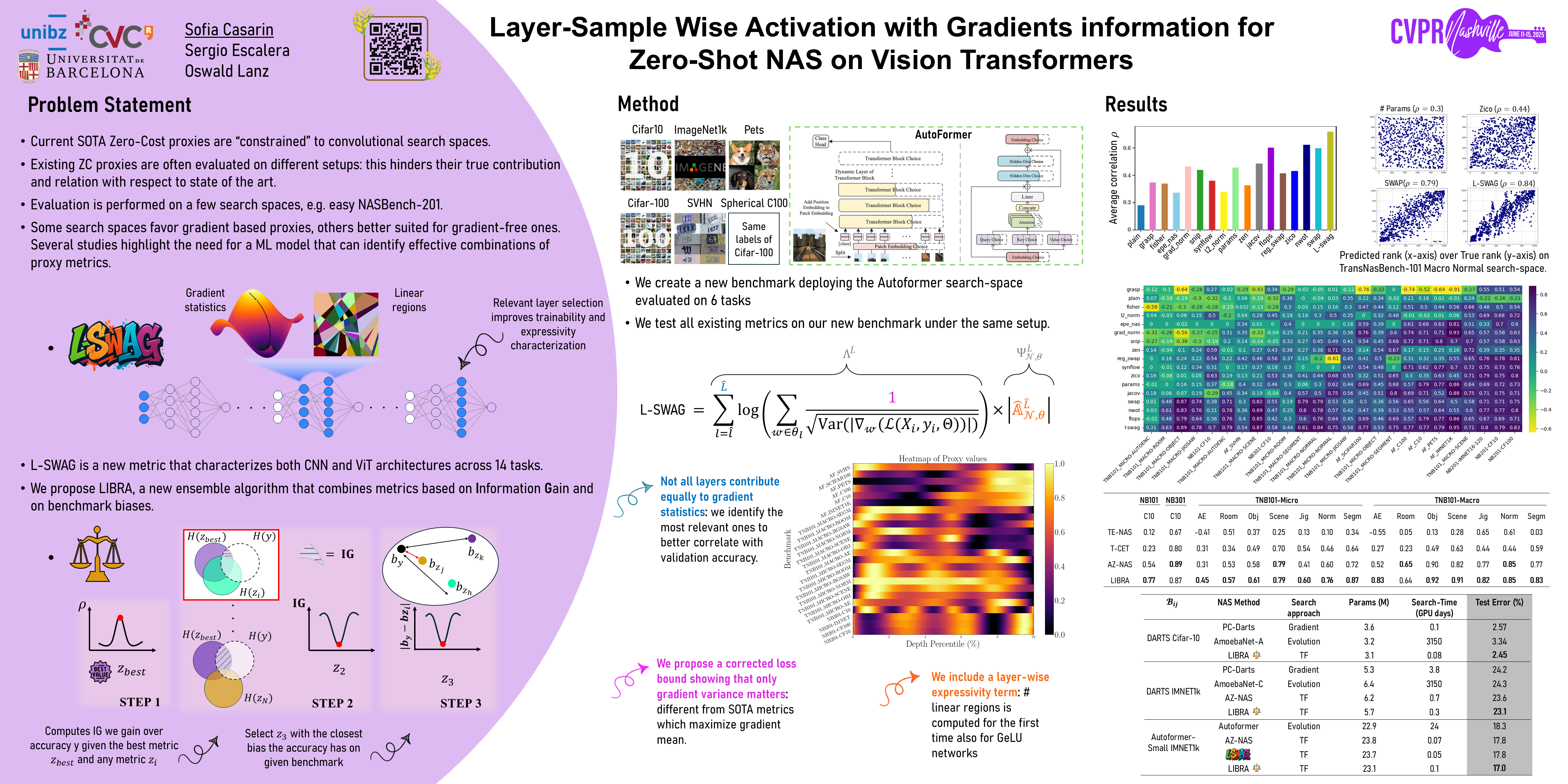
Training-free Neural Architecture Search (NAS) efficiently identifies high-performing neural networks using zero-cost (ZC) proxies. Unlike multi-shot and one-shot NAS approaches, ZC-NAS is both (i) time-efficient, eliminating the need for model training, and (ii) interpretable, with proxy designs often theoretically grounded. Despite rapid developments in the field, current SOTA ZC proxies are typically constrained to well-established convolutional search spaces. With the rise of Large Language Models shaping the future of deep learning, this work extends ZC proxy applicability to Vision Transformers (ViTs). We present a new benchmark using the Autoformer search space evaluated on 6 distinct tasks, and propose Layer-Sample Wise Activation with Gradients information (L-SWAG), a novel, generalizable metric that characterises both convolutional and transformer architectures across 14 tasks. Additionally, previous works highlighted how different proxies contain complementary information, motivating the need for a ML model to identify useful combinations. To further enhance ZC-NAS, we therefore introduce LIBRA-NAS (Low Information gain and Bias Re-Alignment), a method that strategically combines proxies to best represent a specific benchmark. Integrated into the NAS search, LIBRA-NAS outperforms evolution and gradient-based NAS techniques by identifying an architecture with a 17.0% test error on ImageNet1k in just 0.1 GPU days.