Generative Multimodal Pretraining with Discrete Diffusion Timestep Tokens
{kind=link}
Abstract
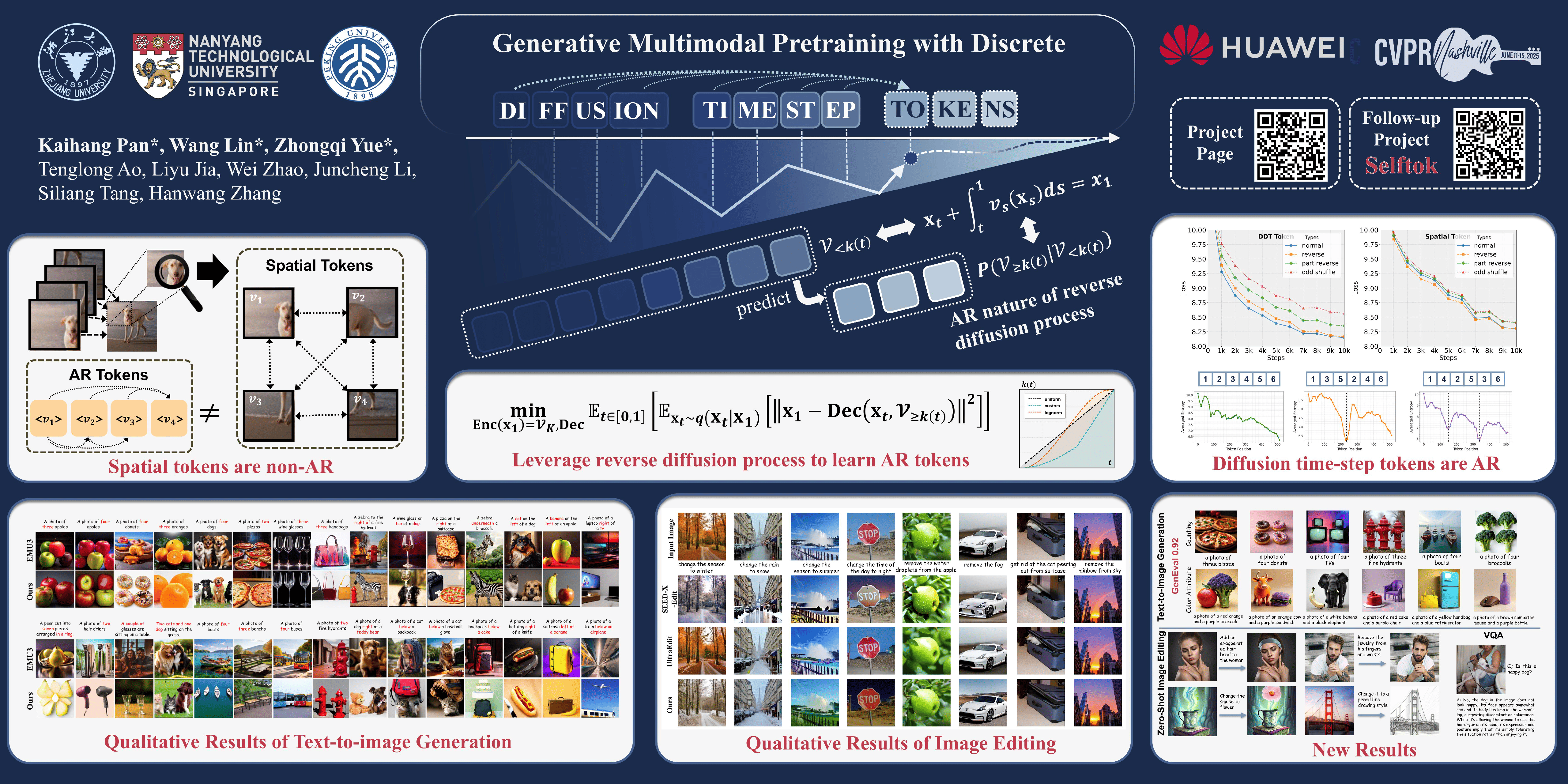
Recent endeavors in Multimodal Large Language Models (MLLMs) aim to unify visual comprehension and generation by combining LLM and diffusion models, the state-of-the-art in each task, respectively. Existing approaches rely on spatial visual tokens, where image patches are encoded and arranged according to a spatial order (e.g., raster scan). However, we show that spatial tokens lack the recursive structure inherent to languages, hence form an impossible language for LLM to master. In this paper, we build a proper visual language by leveraging diffusion timesteps to learn discrete, recursive visual tokens. Our proposed tokens recursively compensate for the progressive attribute loss in noisy images as timesteps increase, enabling the diffusion model to reconstruct the original image at any timestep. This approach allows us to effectively integrate the strengths of LLMs in autoregressive reasoning and diffusion models in precise image generation, achieving seamless multimodal comprehension and generation within a unified framework. Extensive experiments show that we achieve a new SOTA for multimodal comprehension and generation simultaneously compared with other MLLMs.