Not Only Text: Exploring Compositionality of Visual Representations in Vision-Language Models
 Highlight
Highlight
{kind=link}
Abstract
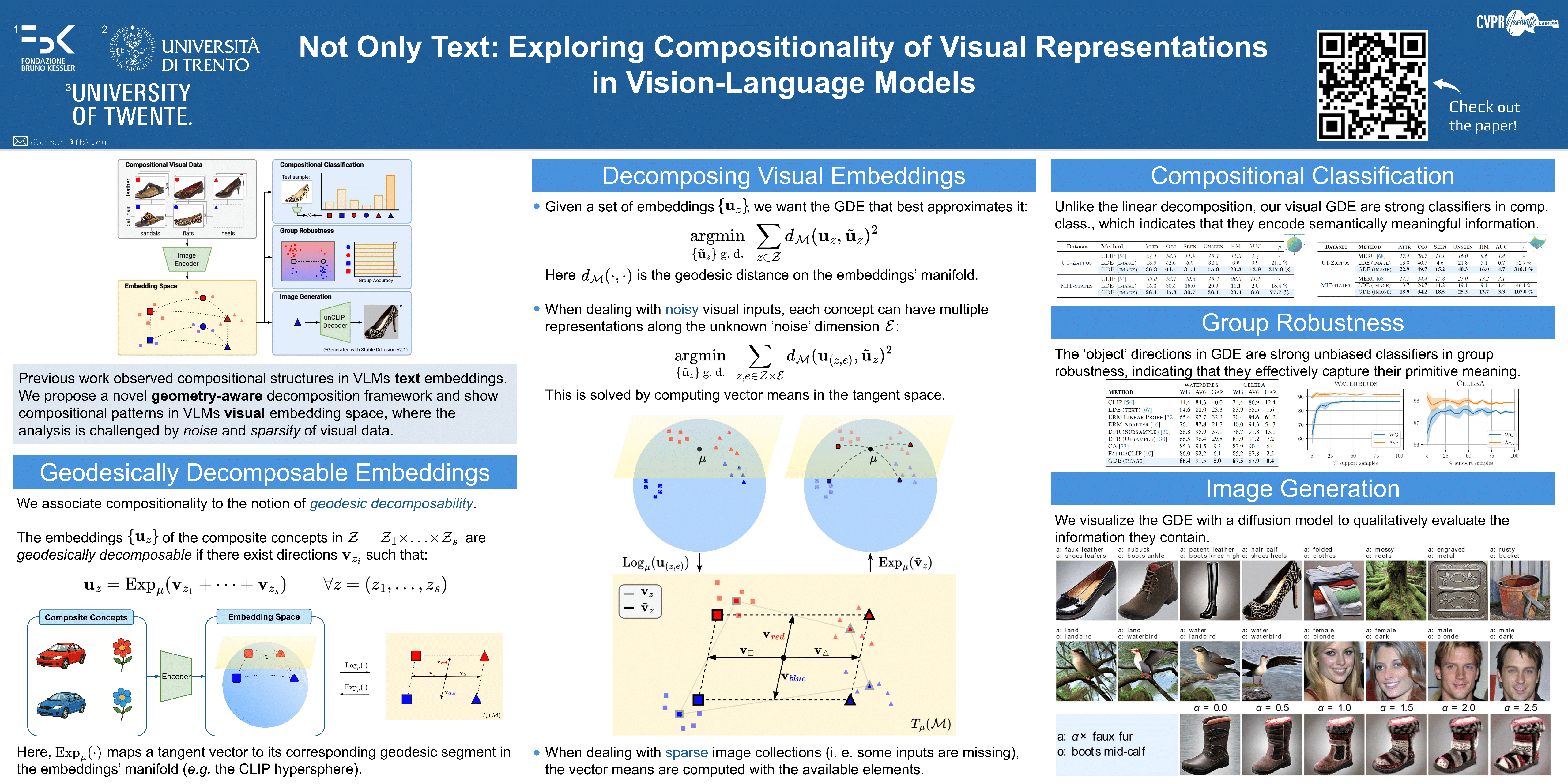
Vision-Language Models (VLMs) learn a shared feature space for text and images, enabling the comparison of inputs of different modalities. While prior works demonstrated that VLMs organize natural language representations into regular structures encoding composite meanings, it remains unclear if compositional patterns also emerge in the visual embedding space. In this work, we investigate compositionality in the image domain, where the analysis of compositional properties is challenged by noise and sparsity of visual data.We propose a framework, called Geodesically Decomposable Embeddings (GDE), that addresses these problems and approximates image representations with geometry-aware compositional structures in the latent space. We demonstrate that visual embeddings of pre-trained VLMs exhibit a compositional arrangement, and evaluate the effectiveness of this property in the tasks of compositional classification and group robustness. GDE achieves stronger performance in compositional classification compared to its counterpart method that assumes linear geometry of the latent space. Notably, it is particularly effective for group robustness, where we achieve higher results than task-specific solutions. Our results indicate that VLMs can automatically develop a human-like form of compositional reasoning in the visual domain, making their underlying processes more interpretable.