Everything to the Synthetic: Diffusion-driven Test-time Adaptation via Synthetic-Domain Alignment
{kind=link}
Abstract
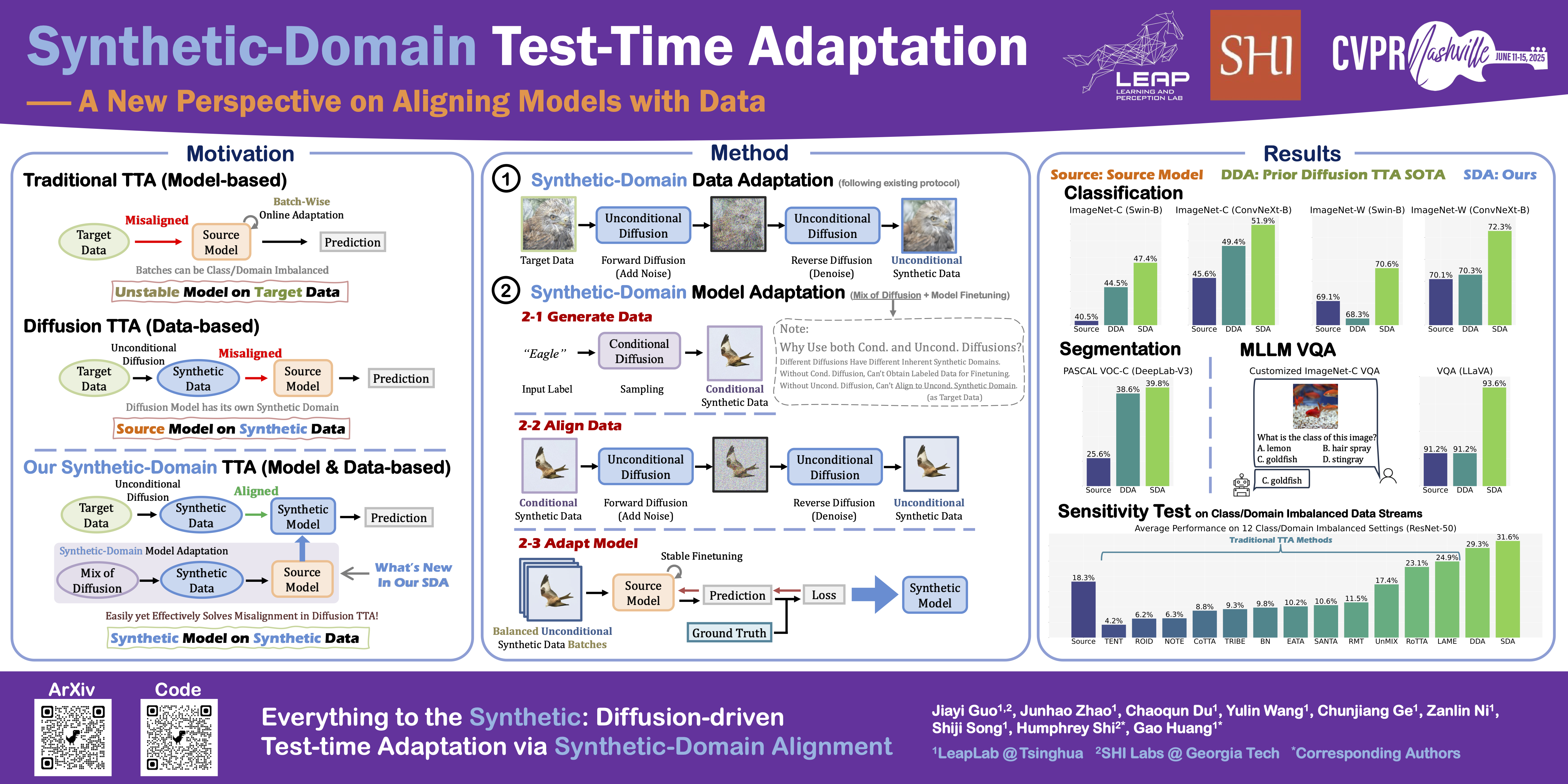
Test-time adaptation (TTA) aims to improve the performance of source-domain pre-trained models on previously unseen, shifted target domains. Traditional TTA methods primarily adapt model weights based on target data streams, making model performance sensitive to the amount and order of target data. The recently proposed diffusion-driven TTA methods mitigate this by adapting model inputs instead of weights, where an unconditional diffusion model, trained on the source domain, transforms target-domain data into a synthetic domain that is expected to approximate the source domain. However, in this paper, we reveal that although the synthetic data in diffusion-driven TTA seems indistinguishable from the source data, it is unaligned with, or even markedly different from the latter for deep networks. To address this issue, we propose a Synthetic-Domain Alignment (SDA) framework. Our key insight is to fine-tune the source model with synthetic data to ensure better alignment. Specifically, we first employ a conditional diffusion model to generate labeled samples, creating a synthetic dataset. Subsequently, we use the aforementioned unconditional diffusion model to add noise to and denoise each sample before fine-tuning. This Mix of Diffusion (MoD) process mitigates the potential domain misalignment between the conditional and unconditional models. Extensive experiments across classifiers, segmenters, and multimodal large language models (MLLMs, \eg, LLaVA) demonstrate that SDA achieves superior domain alignment and consistently outperforms existing diffusion-driven TTA methods. Our code will be open-sourced.