Leveraging Temporal Cues for Semi-Supervised Multi-View 3D Object Detection
{kind=link}
Abstract
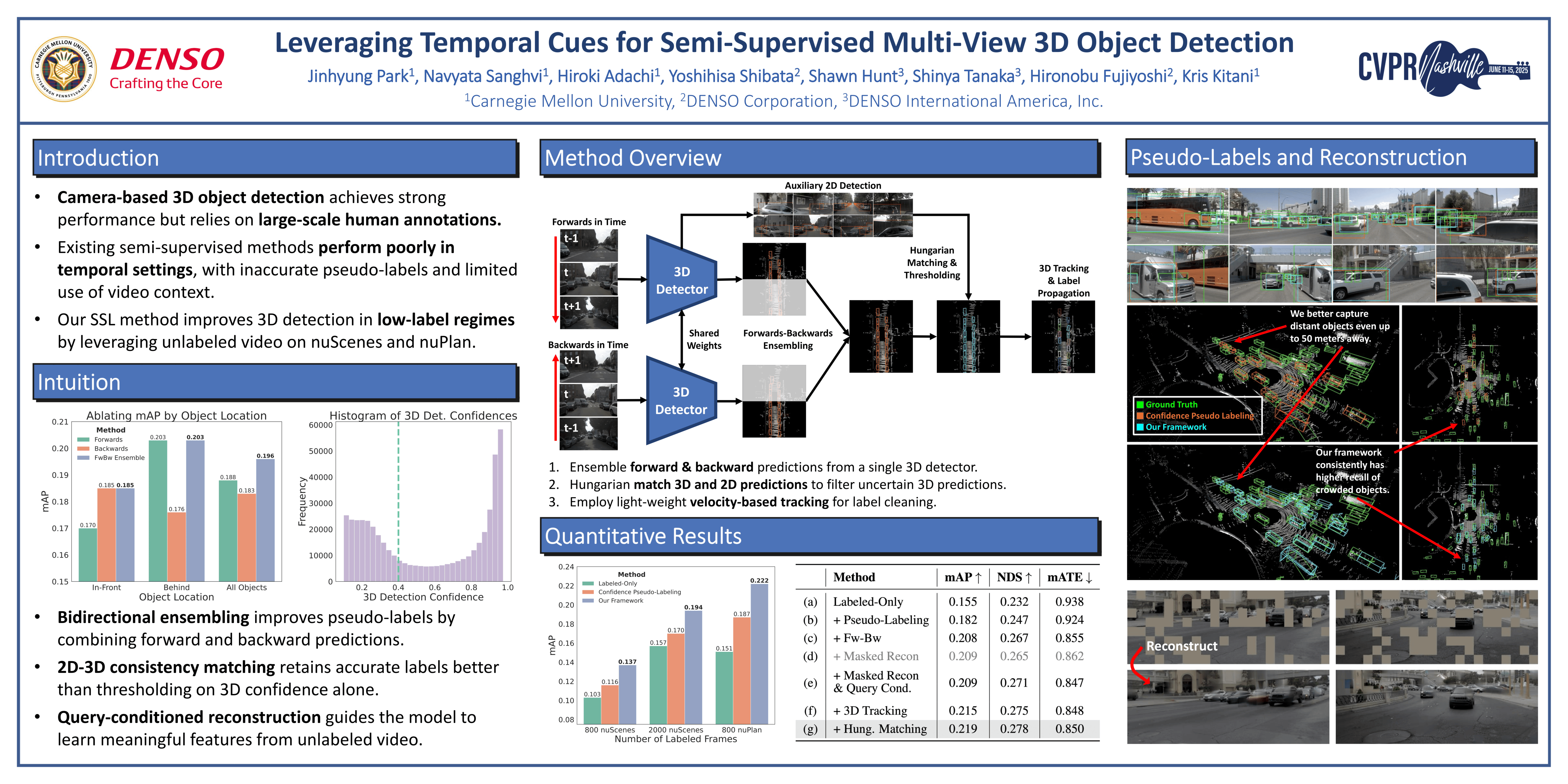
While recent advancements in camera-based 3D object detection demonstrate remarkable performance, they require thousands or even millions of human-annotated frames. This requirement significantly inhibits their deployment in various locations and sensor configurations. To address this gap, we propose a performant semi-supervised framework that leverages unlabeled RGB-only driving sequences - data easily collected with cost-effective RGB cameras - to significantly improve temporal, camera-only 3D detectors. We observe that the standard semi-supervised pseudo-labeling paradigm under-performs in this temporal, camera-only setting due to poor 3D localization of pseudo-labels. To address this, we train a single 3D detector to handle RGB sequences both forwards and backwards in time, then ensemble both its forwards and backwards pseudo-labels for semi-supervised learning. We further improve the pseudo-label quality by leveraging 3D object tracking to in-fill missing detections and by eschewing simple confidence thresholding in favor of using the auxiliary 2D detection head to filter 3D predictions. Finally, to enable the backbone to learn directly from the unlabeled data itself, we introduce an object-query conditioned masked reconstruction objective. Our framework demonstrates remarkable performance improvement on large-scale autonomous driving datasets nuScenes and nuPlan.