FLAVC: Learned Video Compression with Feature Level Attention
{kind=link}
Abstract
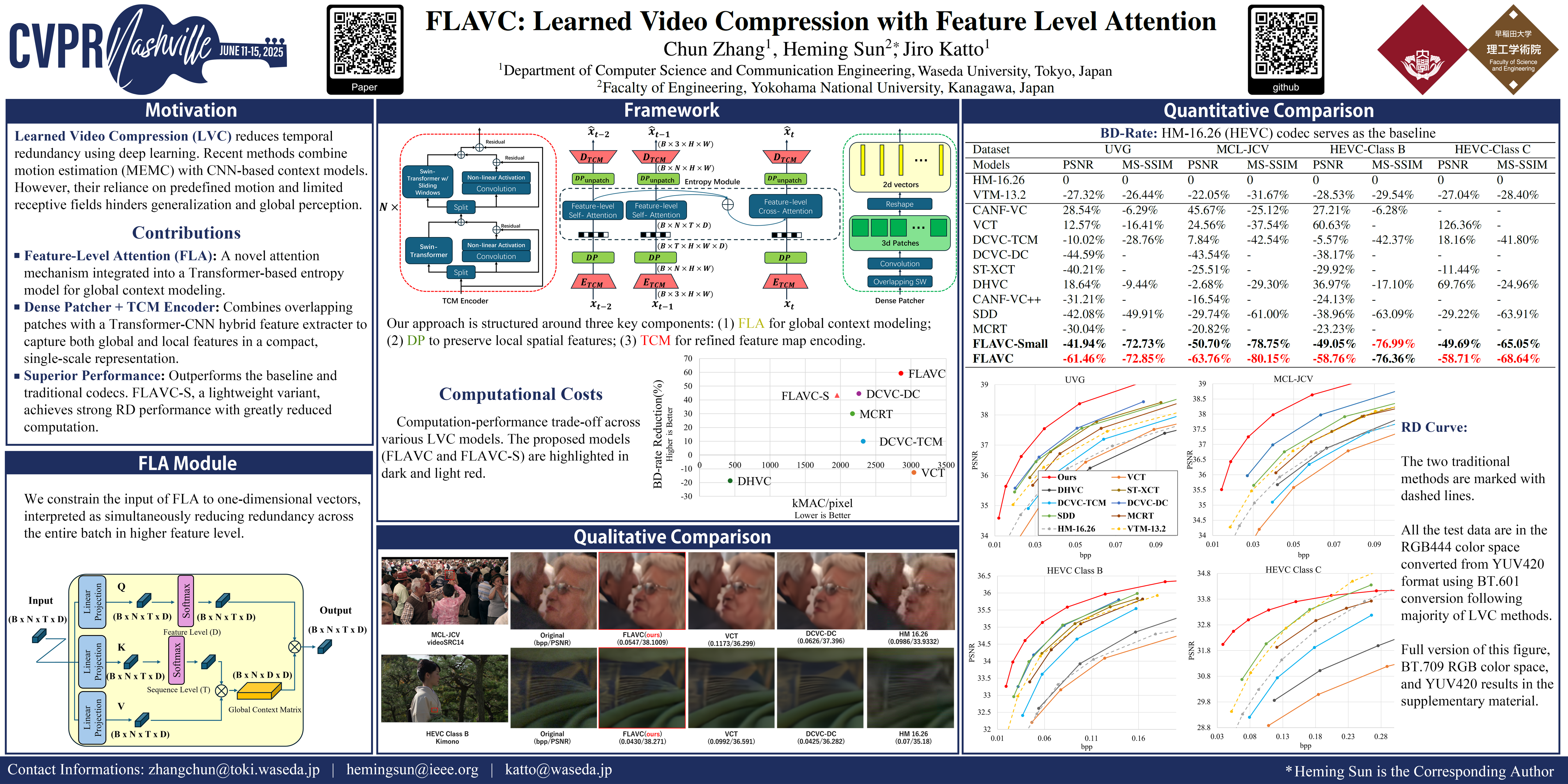
Learned Video Compression (LVC) aims to reduce redundancy in sequential data through deep learning approaches. Recent advances have significantly boosted LVC performance by shifting compression operations to feature domain, often combining Motion Estimation and Motion Compensation module(MEMC) with CNN-based context extraction. However, reliance on motions and convolution-driven context models limits generalizability and global perception. To address these issues, we propose a Feature-level Attention (FLA) module within a Transformer-based framework that perceives full-frame explicitly, thus bypassing confined motion signatures. FLA accomplishes global perception by converting high-level local patch embeddings to one-dimensional batch-wise vectors and replacing traditional attention weights to a global context matrix. Amongst this, a dense overlapping patcher (DP) is introduced to retain local features before embedding projection. Furthermore, a Transformer-CNN mixed encoder is applied to alleviate the spatial feature bottleneck without expanding latent size. Experiments demonstrate excellent generalizability with universally efficient redundancy reduction in different scenarios. Extensive tests on four video compression datasets show that our method achieves state-of-the-art Rate-Distortion performance compared to existing LVC methods and traditional codecs. A down-scaled version of our model reduced computation overhead by a great margin while maintained great performance.