Zero-Shot Styled Text Image Generation, but Make It Autoregressive
{kind=link}
Abstract
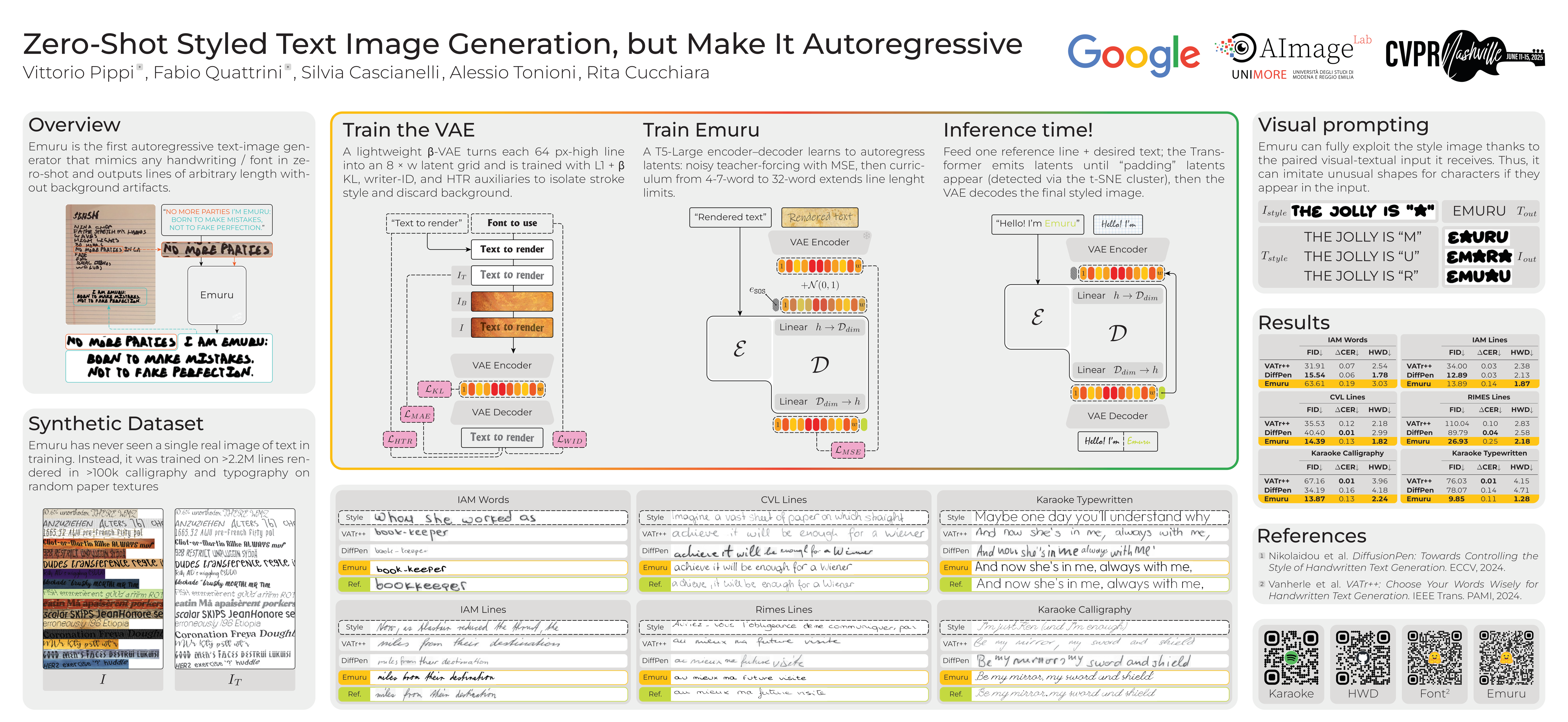
Styled Handwritten Text Generation (HTG) has recently received attention from the computer vision and document analysis communities, which have developed several solutions, either GAN- or diffusion-based, that achieved promising results. Nonetheless, these strategies fail to generalize to novel styles and have technical constraints, particularly in terms of maximum output length and training efficiency. To overcome these limitations, in this work, we propose a novel framework for text-image generation, dubbed Emuru. Our approach leverages a powerful text-image representation model (a variational autoencoder) combined with an autoregressive Transformer. Our approach enables the generation of styled text images conditioned on textual content and style examples, such as specific fonts or handwriting styles. We train our model solely on a diverse, synthetic dataset of English text rendered in over 100,000 typewritten and calligraphy fonts, which gives it the capability to reproduce unseen styles (both fonts and users' handwriting) in zero-shot. To the best of our knowledge, Emuru is the first autoregressive model for HTG, and the first designed specifically for generalization to novel styles. Moreover, our model generates images without background artifacts, which are easier to use for downstream applications. Extensive evaluation on both typewritten and handwritten, any-length text image generation scenarios demonstrates the effectiveness of our approach.