ReWind: Understanding Long Videos with Instructed Learnable Memory
{kind=link}
Abstract
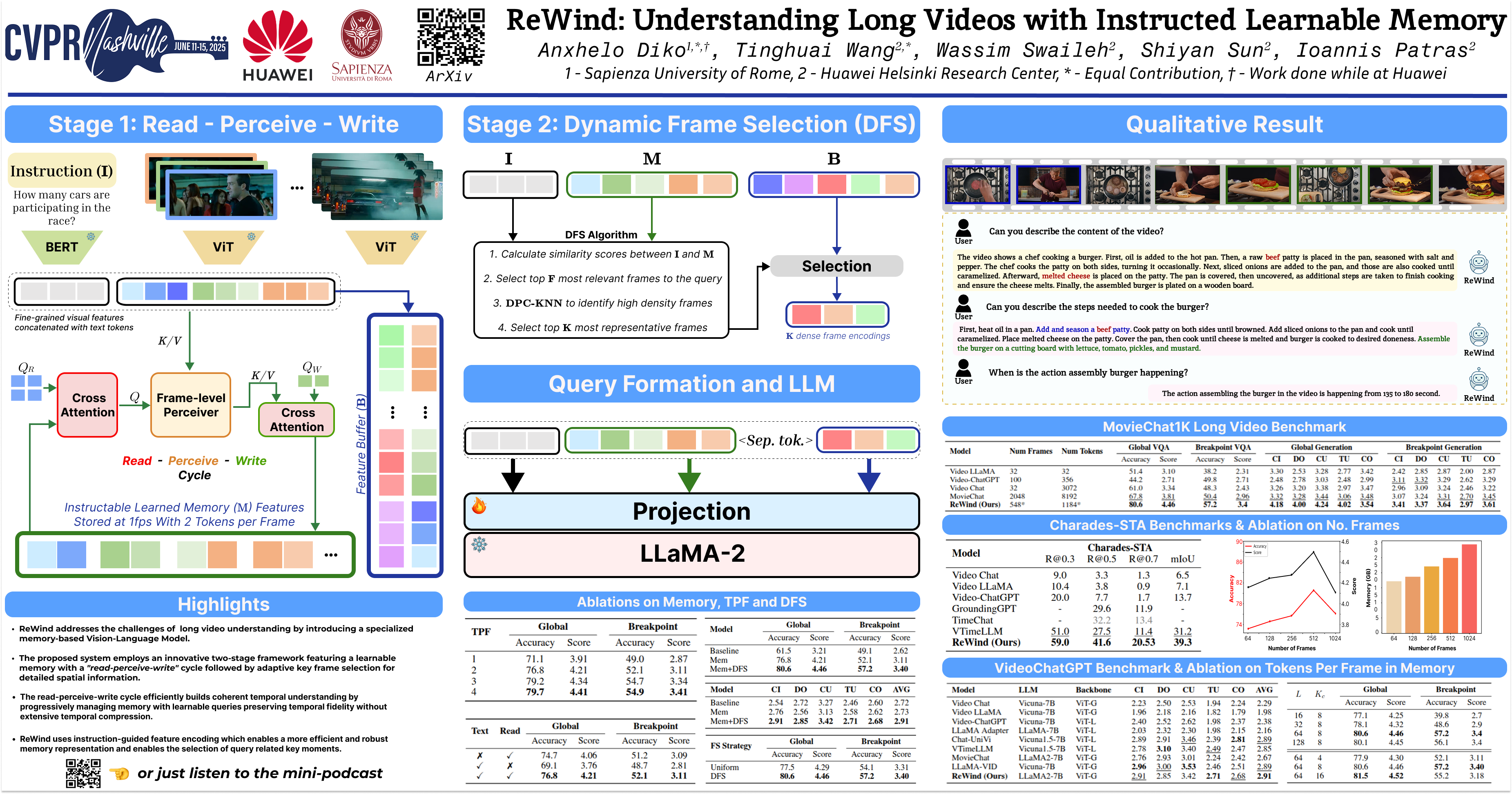
Vision-Language Models (VLMs) are crucial for real-world applications that require understanding textual and visual information. However, existing VLMs face multiple challenges in processing long videos, including computational inefficiency, memory limitations, and difficulties maintaining coherent understanding across extended sequences. These issues stem partly from the quadratic scaling of self-attention w.r.t. number of tokens but also encompass broader challenges in temporal reasoning and information integration over long sequences. To address these challenges, we introduce ReWind, a novel two-stage framework for long video understanding. In the first stage, ReWind maintains a dynamic memory that stores and updates instruction-relevant visual information as the video unfolds.Memory updates leverage novel read and write mechanisms utilizing learnable queries and cross-attentions between memory contents and the input stream. This approach maintains low memory requirements as the cross-attention layers scale linearly w.r.t. number of tokens. In the second stage, the memory content guides the selection of a few relevant frames, represented at high spatial resolution, which are combined with the memory contents and fed into an LLM to generate the final answer. We empirically demonstrate ReWind's superiority in visual question answering (VQA) and temporal grounding tasks, surpassing previous methods on long video benchmarks. Notably, ReWind achieves a +13\% score gain and a +12\% accuracy improvement on the MovieChat-1K VQA dataset and an +8\% mIoU increase on Charades-STA for temporal grounding.