Adapting Pre-trained 3D Models for Point Cloud Video Understanding via Cross-frame Spatio-temporal Perception
{kind=link}
Abstract
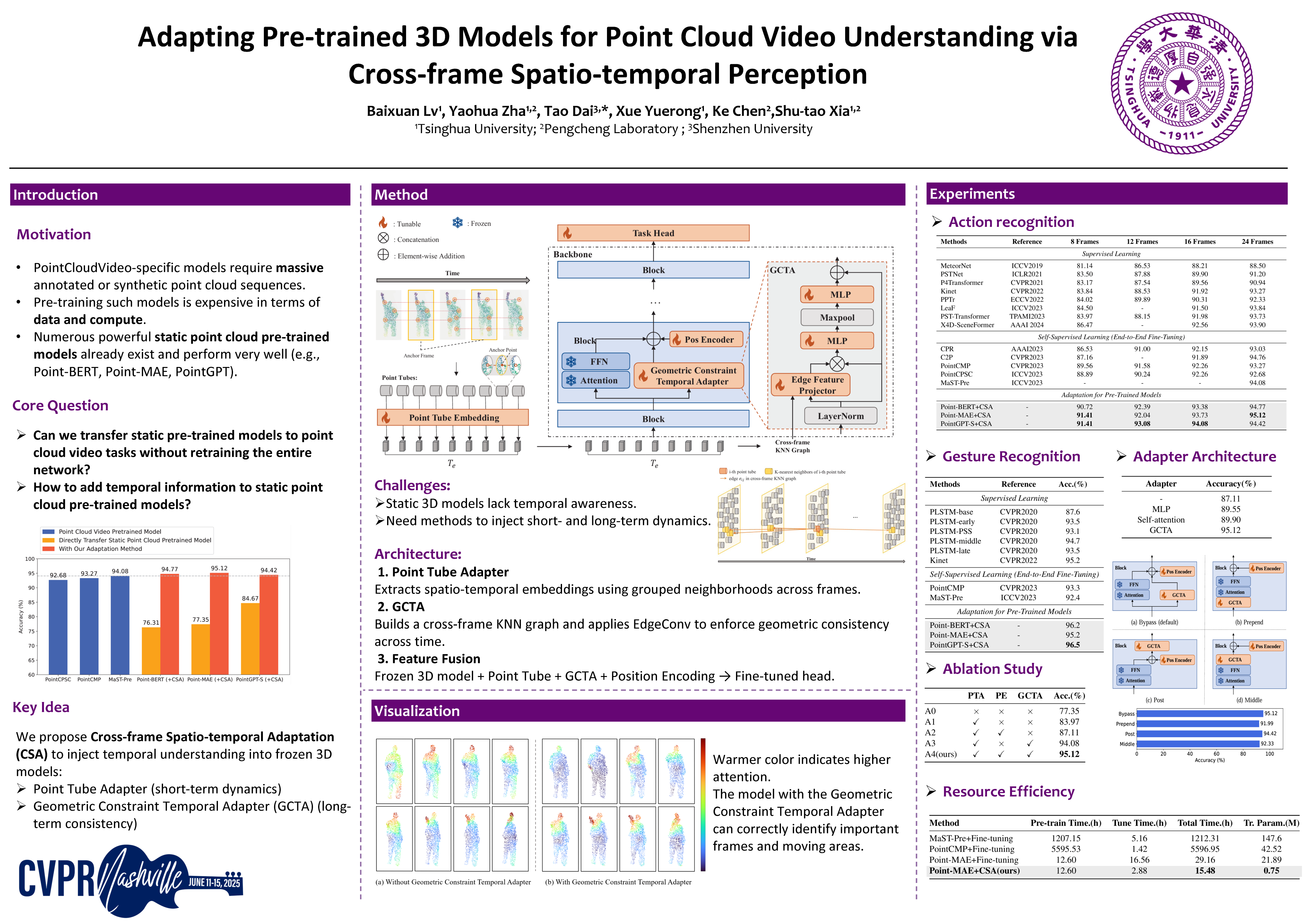
Point cloud video understanding is becoming increasingly important in fields such as robotics, autonomous driving, and augmented reality, as they can accurately represent object motion and environmental changes. Despite the progress made in self-supervised learning methods for point cloud video understanding, the limited availability of 4D data and the high computational cost of training 4D-specific models remain significant obstacles. In this paper, we investigate the potential of transferring pre-trained static 3D point cloud models to the 4D domain, identifying the limitations of static models that capture only spatial information while neglecting temporal dynamics. To address this, we propose a novel Cross-frame Spatio-temporal Adaptation (CSA) strategy by introducing the Point Tube Adapter as the embedding layer and the Geometric Constraint Temporal Adapter (GCTA) to enforce temporal consistency across frames. This strategy extracts both short-term and long-term temporal dynamics, effectively integrating them with spatial features and enriching the model’s understanding of temporal changes in point cloud videos. Extensive experiments on 3D action and gesture recognition tasks demonstrate that our method achieves state-of-the-art performance, establishing its effectiveness for point cloud video understanding.