Diffusion Bridge: Leveraging Diffusion Model to Reduce the Modality Gap Between Text and Vision for Zero-Shot Image Captioning
{kind=link}
Abstract
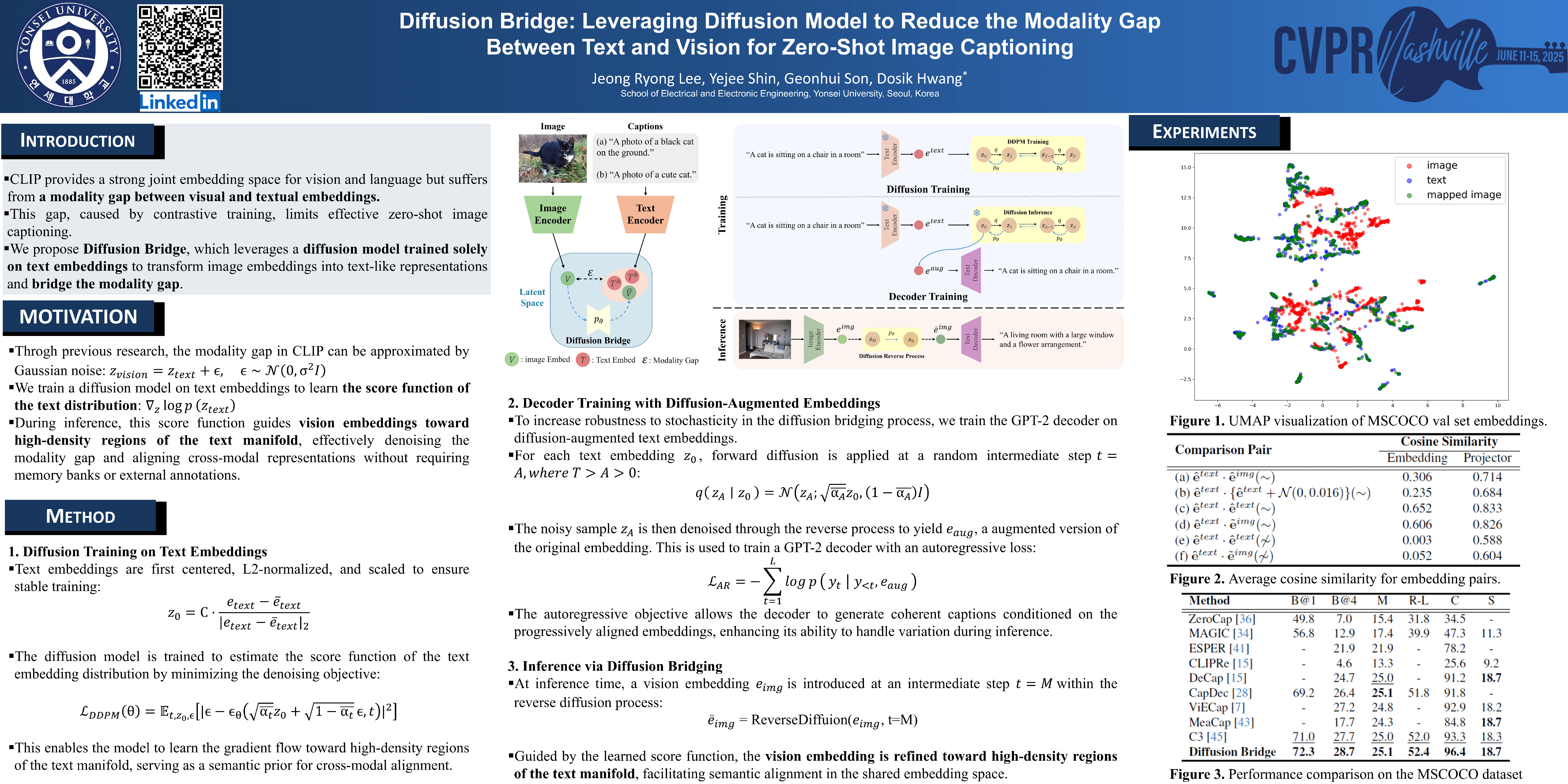
The modality gap between vision and text embeddings in CLIP presents a significant challenge for zero-shot image captioning, limiting effective cross-modal representation. Traditional approaches, such as noise injection and memory-based similarity matching, attempt to address this gap, yet these methods either rely on indirect alignment or relatively naive solutions with heavy computation. Diffusion Bridge introduces a novel approach to directly reduce this modality gap by leveraging Denoising Diffusion Probabilistic Models (DDPM), trained exclusively on text embeddings to model their distribution. Our approach is motivated by the observation that, while paired vision and text embeddings are relatively close, a modality gap still exists due to stable regions created by the contrastive loss. This gap can be interpreted as noise in cross-modal mappings, which we approximate as Gaussian noise. To bridge this gap, we employ a reverse diffusion process, where image embeddings are strategically introduced at an intermediate step in the reverse process, allowing them to be refined progressively toward the text embedding distribution. This process transforms vision embeddings into text-like representations closely aligned with paired text embeddings, effectively minimizing residual discrepancies. Experimental results demonstrate that these text-like vision embeddings significantly enhance alignment with their paired text embeddings, leading to improved zero-shot captioning performance on MSCOCO and Flickr30K. Diffusion Bridge achieves competitive results without reliance on memory banks or entity-driven methods, offering a streamlined and effective pathway for cross-modal alignment and opening new possibilities for the application of diffusion models in multi-modal tasks.