Ges3ViG : Incorporating Pointing Gestures into Language-Based 3D Visual Grounding for Embodied Reference Understanding
Atharv Mahesh Mane ⋅ Dulanga Weerakoon ⋅ Vigneshwaran Subbaraju ⋅ Sougata Sen ⋅ Sanjay Sarma ⋅ Archan Misra
2025 Poster
{kind=link}
Abstract
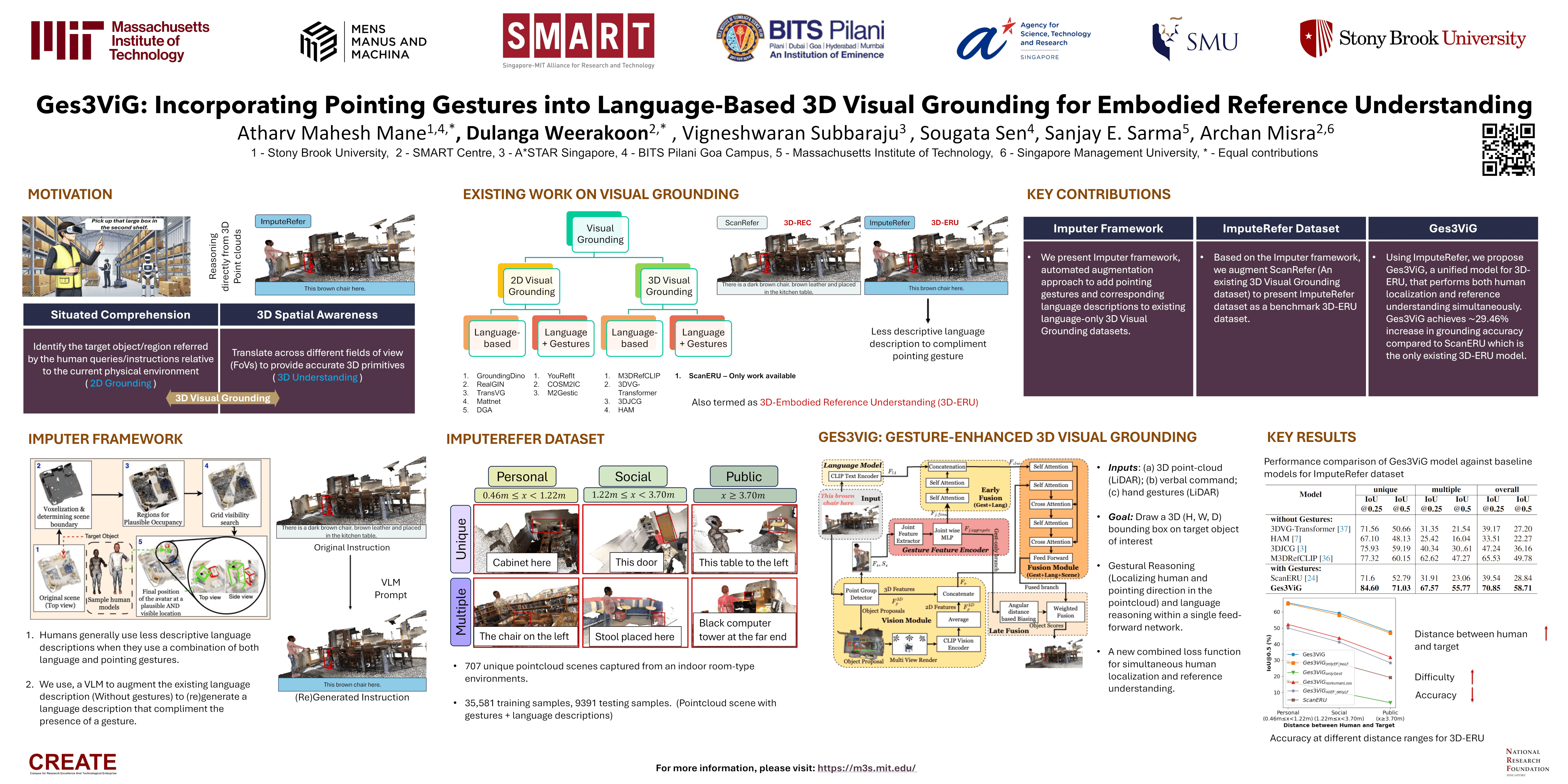
3-Dimensional Embodied Reference Understanding (3D-ERU) is a complex vision-language task, crucial for supporting interactions between humans and situated AI agents. 3D-ERU combines a language description and an accompanying pointing gesture to identify the most relevant target object in a given 3D scene. While previous research has extensively explored pure language-based 3D grounding, there has been limited exploration of 3D-ERU, which also incorporates human pointing gestures. To address this gap, we introduce a data augmentation framework-- **Imputer**, and use it to curate a new challenging benchmark dataset-- **ImputeRefer** for 3D-ERU, by incorporating human pointing gestures into existing 3D scene datasets that only contain language instructions. We also propose **Ges3ViG**, a novel model for 3D-ERU that achieves a $\sim$30\% improvement in accuracy, compared to other 3D-ERU models and $\sim$9\% compared to other purely language-based 3D grounding models. Our code and data will be released publicly upon acceptance of the paper.
Chat is not available.
Successful Page Load