SimMotionEdit: Text-Based Human Motion Editing with Motion Similarity Prediction
{kind=link}
Abstract
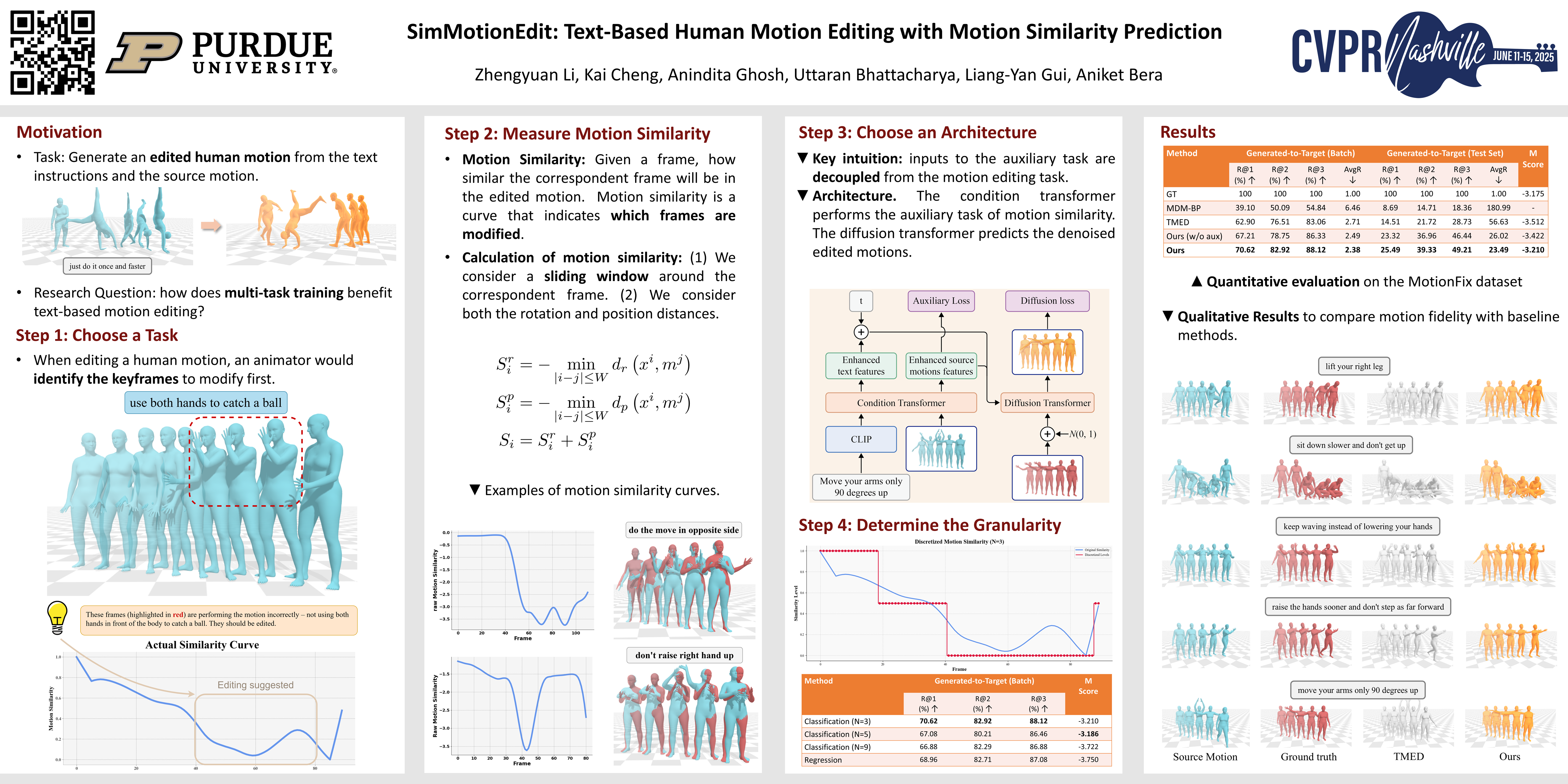
Text-based 3D human motion editing is a critical yet challenging task in computer vision and graphics. While training-free approaches have been explored, the recent release of the MotionFix dataset, which includes source-text-motion triplets, has opened new avenues for training, yielding promising results. However, existing methods struggle with precise control, often resulting in misalignment between motion semantics and language instructions. In this paper, we introduce MotionDiT, an advanced Diffusion-Transformer-based motion editing model that effectively incorporates editing features both as layer-wise control signals and as input prefixes. To enhance the model's semantic understanding, we also propose a novel auxiliary task, motion similarity prediction, which fosters the learning of semantically meaningful representations. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in both editing alignment and fidelity.