GRAE-3DMOT: Geometry Relation-Aware Encoder for Online 3D Multi-Object Tracking
{kind=link}
Abstract
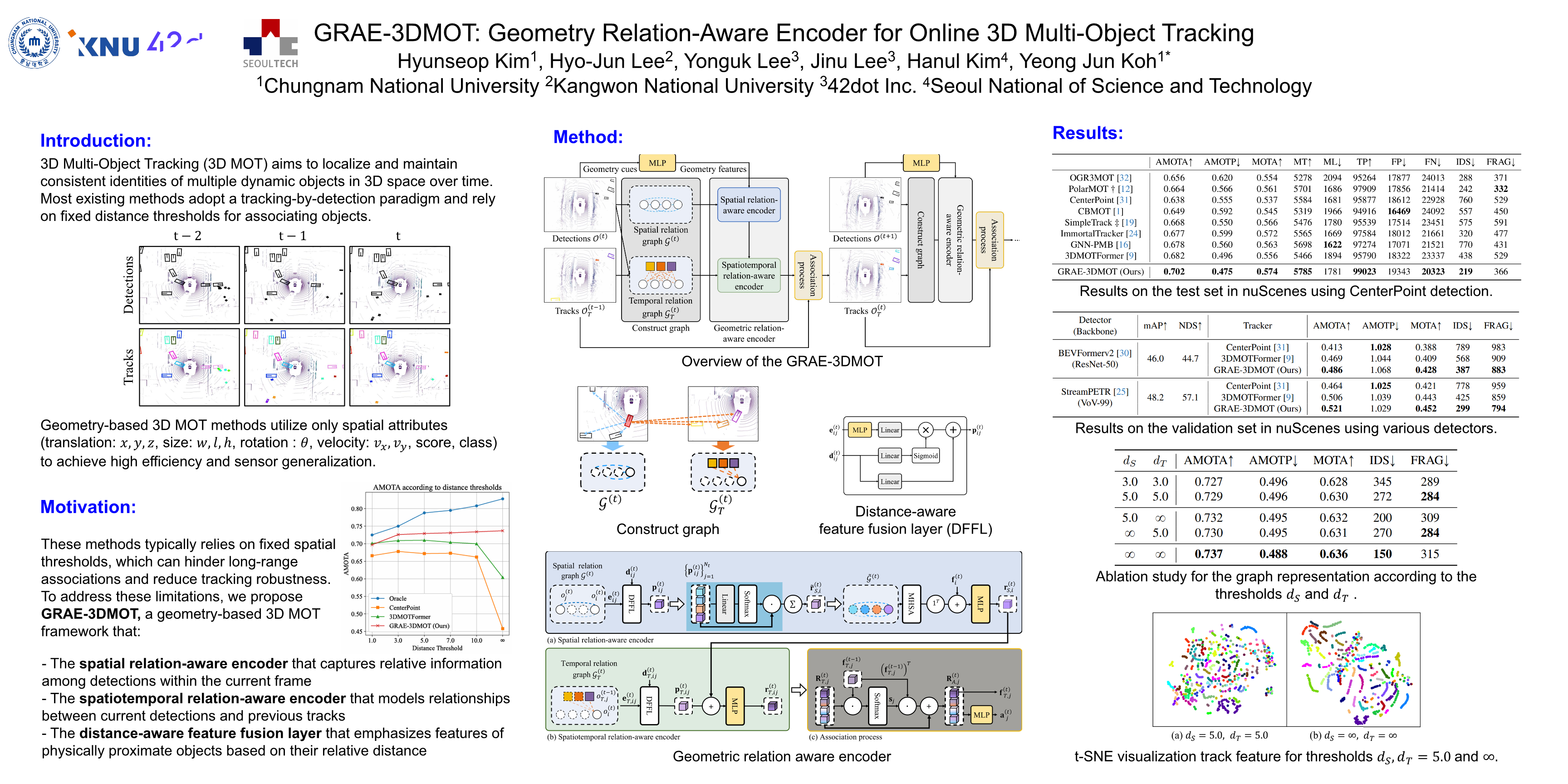
Recently, 3D multi-object tracking (MOT) has widely adopted the standard tracking-by-detection paradigm, which solves the association problem between detections and tracks. Many tracking-by-detection approaches establish constrained relationships between detections and tracks using a distance threshold to reduce confusion during association. However, this approach does not effectively and comprehensively utilize the information regarding objects due to the constraints of the distance threshold. In this paper, we propose GRAE-3DMOT, Geometry Relation-Aware Encoder 3D Multi-Object Tracking, which contains a geometric relation-aware encoder to produce informative features for association. The geometric relation-aware encoder consists of three components: a spatial relation-aware encoder, a spatiotemporal relation-aware encoder, and a distance-aware feature fusion layer. The spatial relation-aware encoder effectively aggregates detection features by comprehensively exploiting as many detections as possible. The spatiotemporal relation-aware encoder provides spatiotemporal relation-aware features by combing spatial and temporal relation features, where the spatiotemporal relation-aware features are transformed into association scores for MOT. The distance-aware feature fusion layer is integrated into both encoders to enhance the relation features of physically proximate objects. Experimental results demonstrate that the proposed GRAE-3DMOT outperforms the state-of-the-art on the nuScenes. Our approach achieves 73.7% and 70.2% AMOTA on the nuScenes validation and test sets using CenterPoint detections.