Learning Conditional Space-Time Prompt Distributions for Video Class-Incremental Learning
 Highlight
Highlight
{kind=link}
Abstract
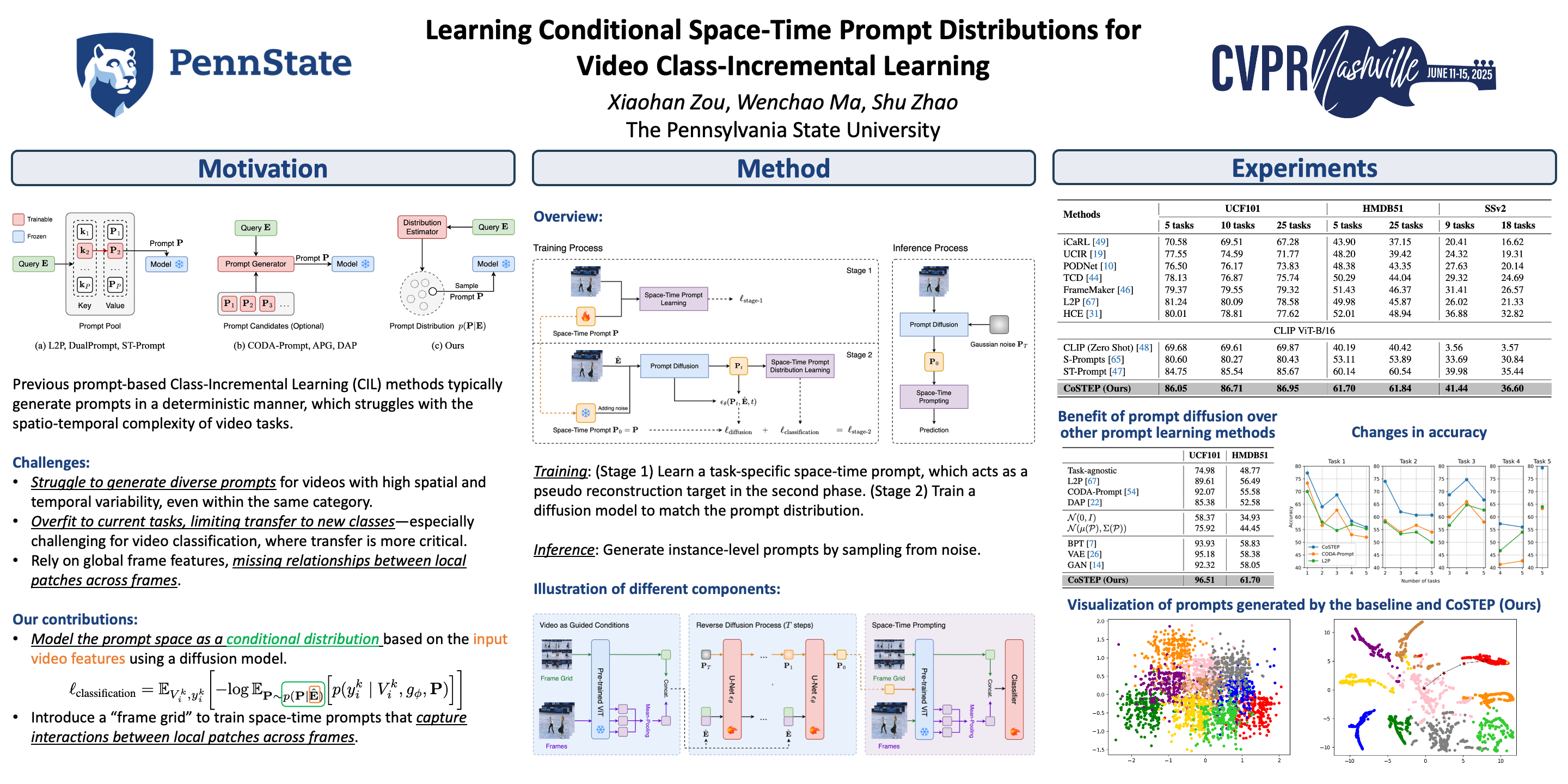
Recent advancements in prompt-based learning have significantly advanced image and video class-incremental learning. However, the prompts learned by these methods often fail to capture the diverse and informative characteristics of videos, and struggle to generalize effectively to future tasks and classes. To address these challenges, this paper proposes modeling the distribution of space-time prompts conditioned on the input video using a diffusion model. This generative approach allows the proposed model to naturally handle the diverse characteristics of videos, leading to more robust prompt learning and enhanced generalization capabilities. Additionally, we develop a mechanism that transfers the token relationship modeling capabilities of a pre-trained image transformer to spatio-temporal modeling for videos. Our approach has been thoroughly evaluated across four established benchmarks, showing remarkable improvements over existing state-of-the-art methods in video class-incremental learning.