UNIALIGN: Scaling Multimodal Alignment within One Unified Model
bo zhou ⋅ Liulei Li ⋅ Yujia Wang ⋅ 刘华峰 Liu ⋅ Yazhou Yao ⋅ Wenguan Wang
2025 Poster
{kind=link}
Abstract
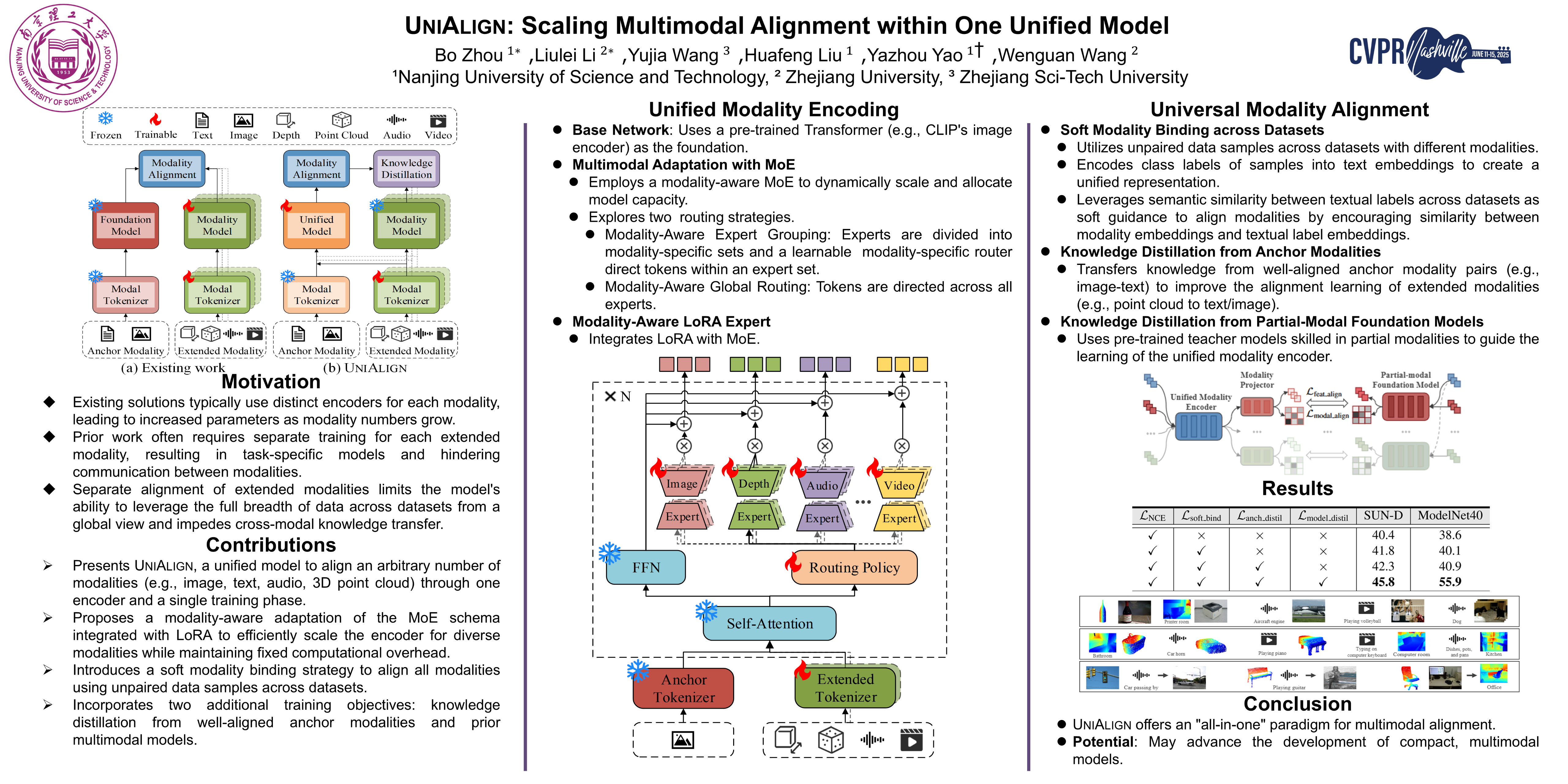
We present UNIALIGN, a unified model to align an arbitrary number of modalities ($\text{e.g.}$, image, text, audio, 3D point cloud, $\textit{etc.}$) through one encoder and a single training phase. Existing solutions typically employ distinct encoders for each modality, resulting in increased parameters as the number of modalities grows. In contrast, UNIALIGN proposes a modality-aware adaptation of the powerful mixture-of-experts (MoE) schema and further integrates it with Low-Rank Adaptation (LoRA), efficiently scaling the encoder to accommodate inputs in diverse modalities while maintaining a fixed computational overhead.Moreover, prior work often requires separate training for each extended modality. This leads to task-specific models and further hinders the communication between modalities.To address this, we propose a soft modality binding strategy that aligns all modalities using unpaired data samples across datasets. Two additional training objectives are introduced to distill knowledge from well-aligned anchor modalities and prior multimodal models, elevating UNIALIGN into a high performance multimodal foundation model.Experiments on 11 benchmarks across 6 different modalities demonstrate that UNIALIGN could achieve comparable performance to SOTA approaches, while using merely 7.8M trainable parameters and maintaining an identical model with the same weight across all tasks. Our code shall be released.
Chat is not available.
Successful Page Load