PlaneDepth: Self-Supervised Depth Estimation via Orthogonal Planes
{kind=link}
Abstract
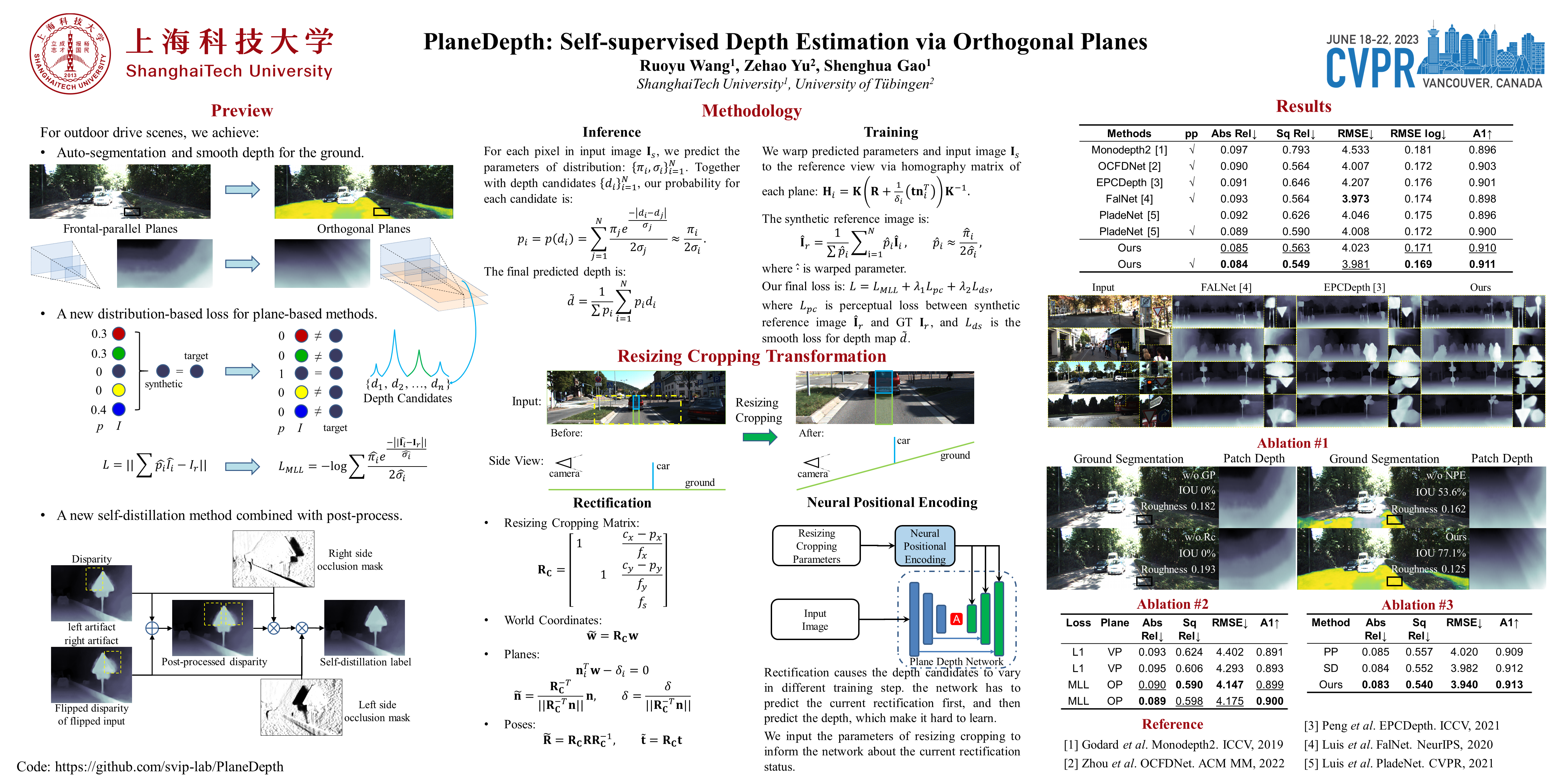
Multiple near frontal-parallel planes based depth representation demonstrated impressive results in self-supervised monocular depth estimation (MDE). Whereas, such a representation would cause the discontinuity of the ground as it is perpendicular to the frontal-parallel planes, which is detrimental to the identification of drivable space in autonomous driving. In this paper, we propose the PlaneDepth, a novel orthogonal planes based presentation, including vertical planes and ground planes. PlaneDepth estimates the depth distribution using a Laplacian Mixture Model based on orthogonal planes for an input image. These planes are used to synthesize a reference view to provide the self-supervision signal. Further, we find that the widely used resizing and cropping data augmentation breaks the orthogonality assumptions, leading to inferior plane predictions. We address this problem by explicitly constructing the resizing cropping transformation to rectify the predefined planes and predicted camera pose. Moreover, we propose an augmented self-distillation loss supervised with a bilateral occlusion mask to boost the robustness of orthogonal planes representation for occlusions. Thanks to our orthogonal planes representation, we can extract the ground plane in an unsupervised manner, which is important for autonomous driving. Extensive experiments on the KITTI dataset demonstrate the effectiveness and efficiency of our method. The code is available at https://github.com/svip-lab/PlaneDepth.