Rethinking Domain Generalization for Face Anti-Spoofing: Separability and Alignment
{kind=link}
Abstract
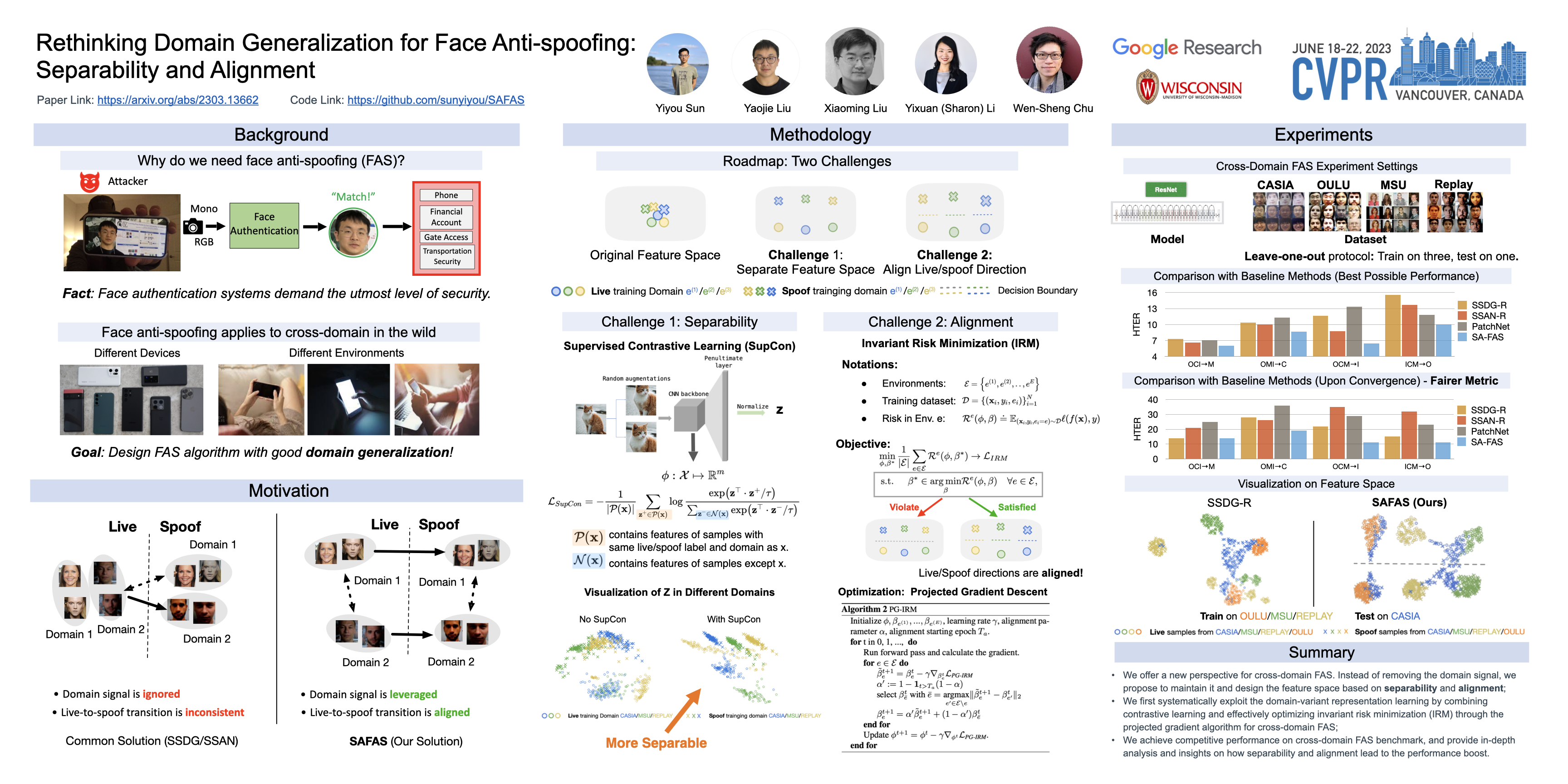
This work studies the generalization issue of face anti-spoofing (FAS) models on domain gaps, such as image resolution, blurriness and sensor variations. Most prior works regard domain-specific signals as a negative impact, and apply metric learning or adversarial losses to remove it from feature representation. Though learning a domain-invariant feature space is viable for the training data, we show that the feature shift still exists in an unseen test domain, which backfires on the generalizability of the classifier. In this work, instead of constructing a domain-invariant feature space, we encourage domain separability while aligning the live-to-spoof transition (i.e., the trajectory from live to spoof) to be the same for all domains. We formulate this FAS strategy of separability and alignment (SA-FAS) as a problem of invariant risk minimization (IRM), and learn domain-variant feature representation but domain-invariant classifier. We demonstrate the effectiveness of SA-FAS on challenging cross-domain FAS datasets and establish state-of-the-art performance.