KiUT: Knowledge-Injected U-Transformer for Radiology Report Generation
{kind=link}
Abstract
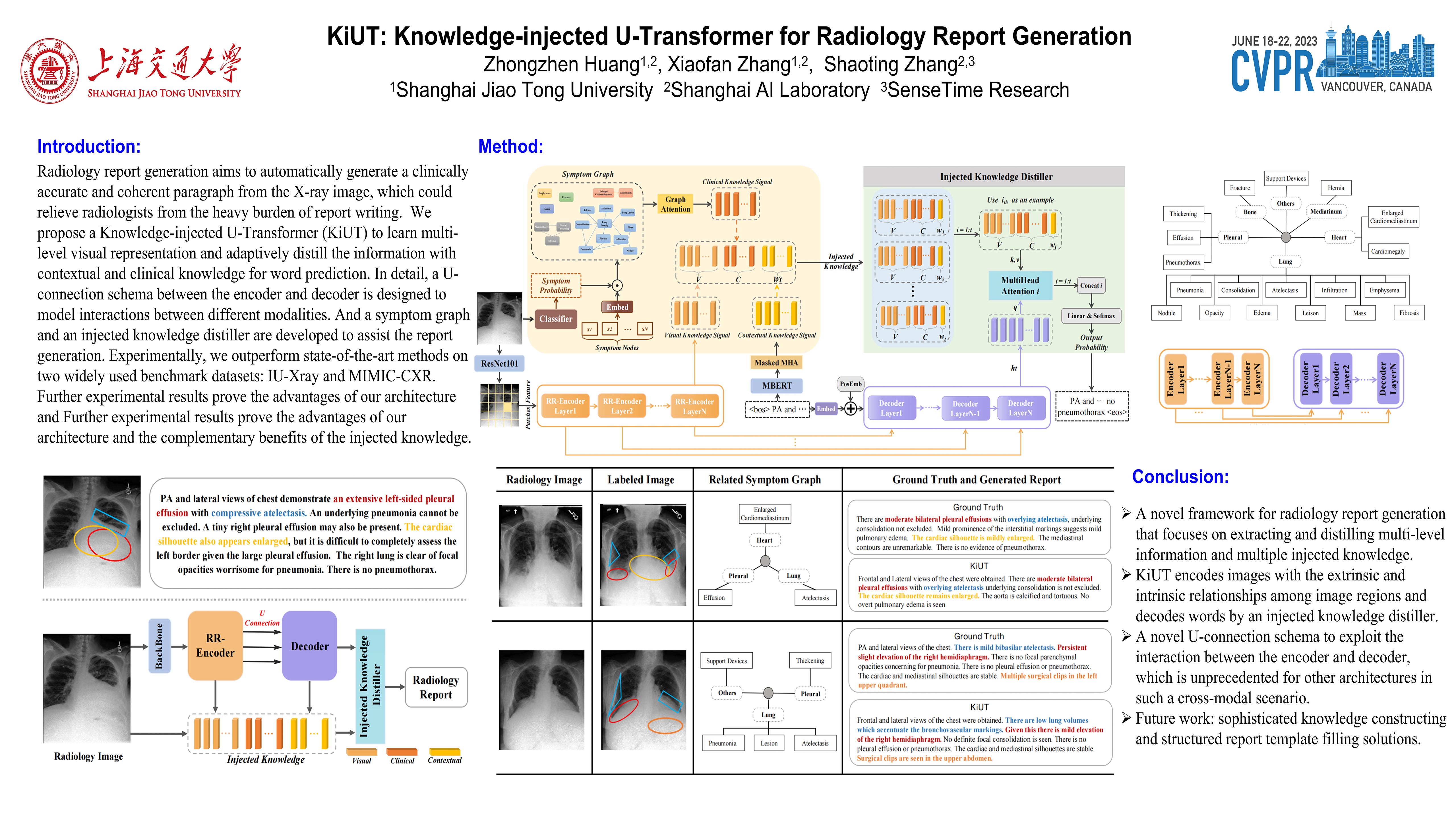
Radiology report generation aims to automatically generate a clinically accurate and coherent paragraph from the X-ray image, which could relieve radiologists from the heavy burden of report writing. Although various image caption methods have shown remarkable performance in the natural image field, generating accurate reports for medical images requires knowledge of multiple modalities, including vision, language, and medical terminology. We propose a Knowledge-injected U-Transformer (KiUT) to learn multi-level visual representation and adaptively distill the information with contextual and clinical knowledge for word prediction. In detail, a U-connection schema between the encoder and decoder is designed to model interactions between different modalities. And a symptom graph and an injected knowledge distiller are developed to assist the report generation. Experimentally, we outperform state-of-the-art methods on two widely used benchmark datasets: IU-Xray and MIMIC-CXR. Further experimental results prove the advantages of our architecture and the complementary benefits of the injected knowledge.