Learning Audio-guided Video Representation with Gated Attention for Video-Text Retrieval
{kind=link}
Abstract
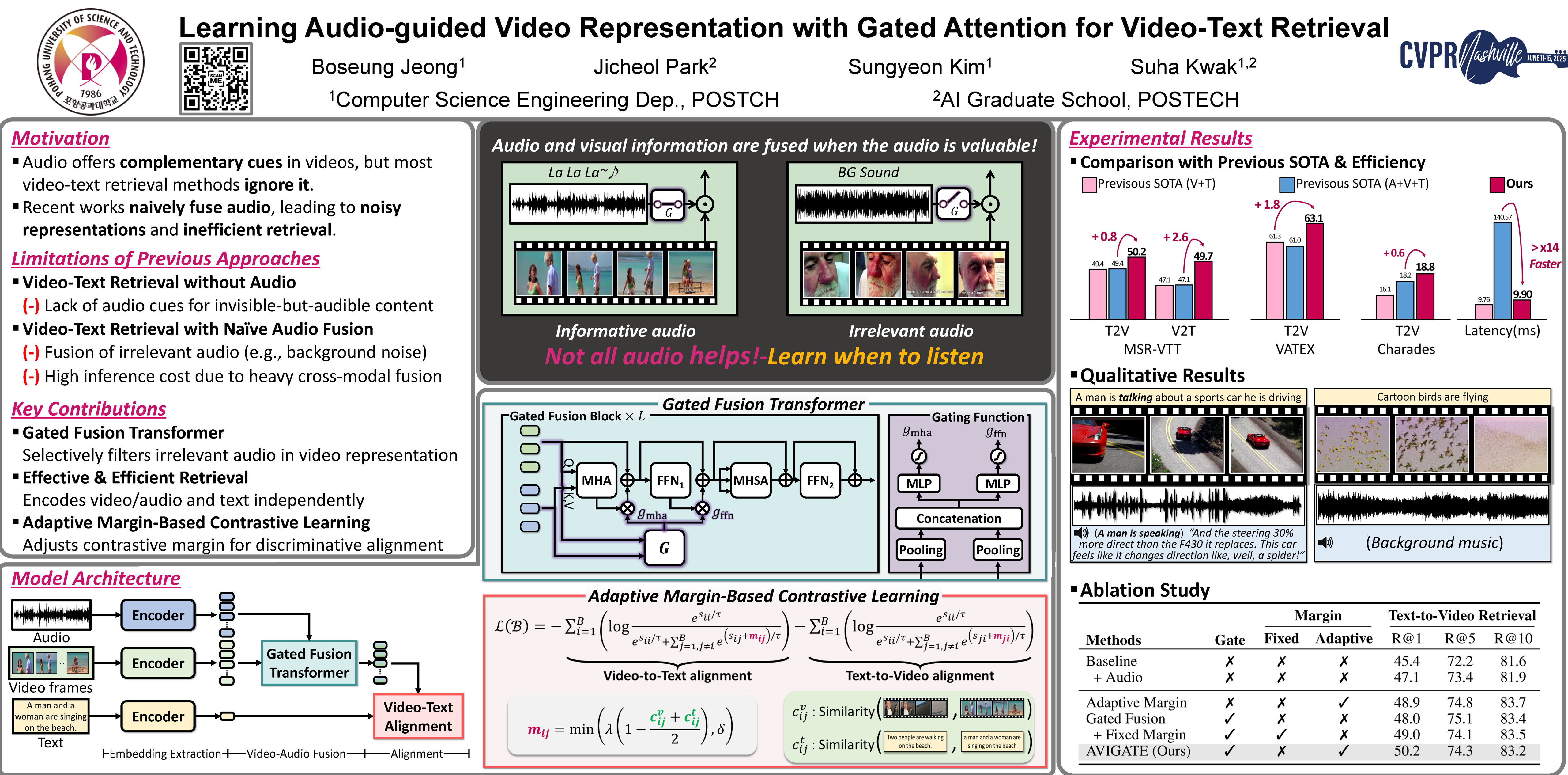
Video-text retrieval, the task of retrieving videos based on a textual query or vice versa, is of paramount importance for video understanding and multimodal information retrieval. Recent methods in this area rely primarily on visual and textual features and often ignore audio, although it helps enhance overall comprehension of video content.Moreover, traditional models that incorporate audio blindly utilize the audio input regardless of whether it is useful or not, resulting in suboptimal video representation. To address these limitations, we propose a novel video-text retrieval framework, Audio-guided VIdeo representation learning with GATEd attention (AVIGATE), that effectively leverages audio cues through a gated attention mechanism that selectively filters out uninformative audio signals.In addition, we propose an adaptive margin-based contrastive loss to deal with the inherently unclear positive-negative relationship between video and text, which facilitates learning better video-text alignment.Our extensive experiments demonstrate that AVIGATE achieves state-of-the-art performance on all the public benchmarks.