Distilling Long-tailed Datasets
{kind=link}
Abstract
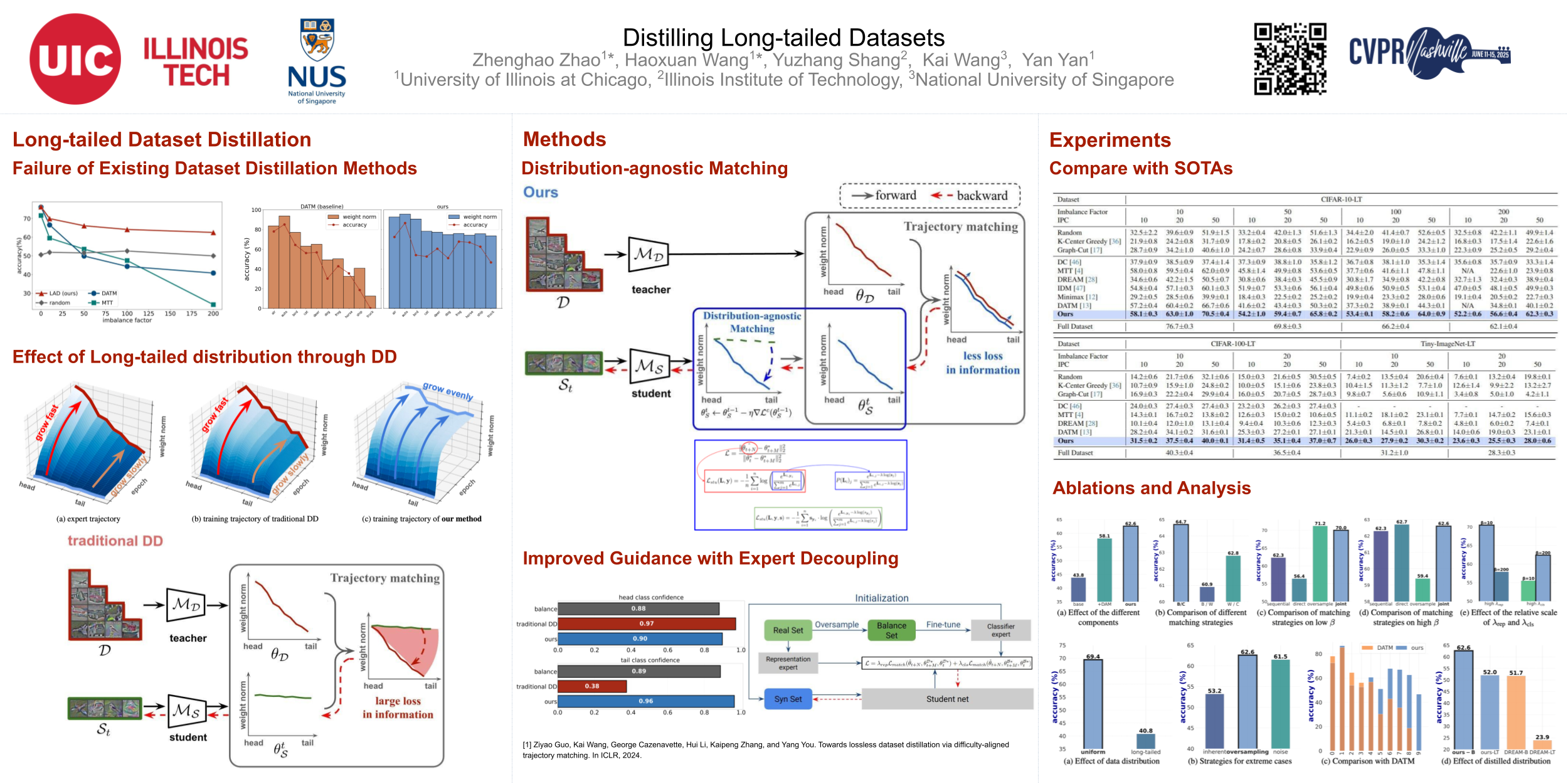
Dataset distillation (DD) aims to synthesize a small information-rich dataset from a large dataset for efficient neural network training. However, existing dataset distillation methods struggle with long-tailed datasets, which are prevalent in real-world scenarios. By investigating the reasons behind this unexpected result, we identified two main causes: 1) The distillation process on imbalanced datasets develops biased gradients, leading to the synthesis of similarly imbalanced distilled datasets. 2) The experts trained on such datasets perform suboptimally on tail classes, resulting in misguided distillation supervision and poor-quality soft-label initialization. To address these issues, we first propose Distribution-agnostic Matching to avoid directly matching the biased expert trajectories. It reduces the distance between the student and the biased expert trajectories and prevents the tail class bias from being distilled to the synthetic dataset. Moreover, we improve the distillation guidance with Expert Decoupling, which jointly matches the decoupled backbone and classifier to improve the tail class performance and initialize reliable soft labels. This work pioneers the field of long-tailed dataset distillation (LTDD), marking the first effective effort to distill long-tailed datasets.