FineLIP: Extending CLIP’s Reach via Fine-Grained Alignment with Longer Text Inputs
{kind=link}
Abstract
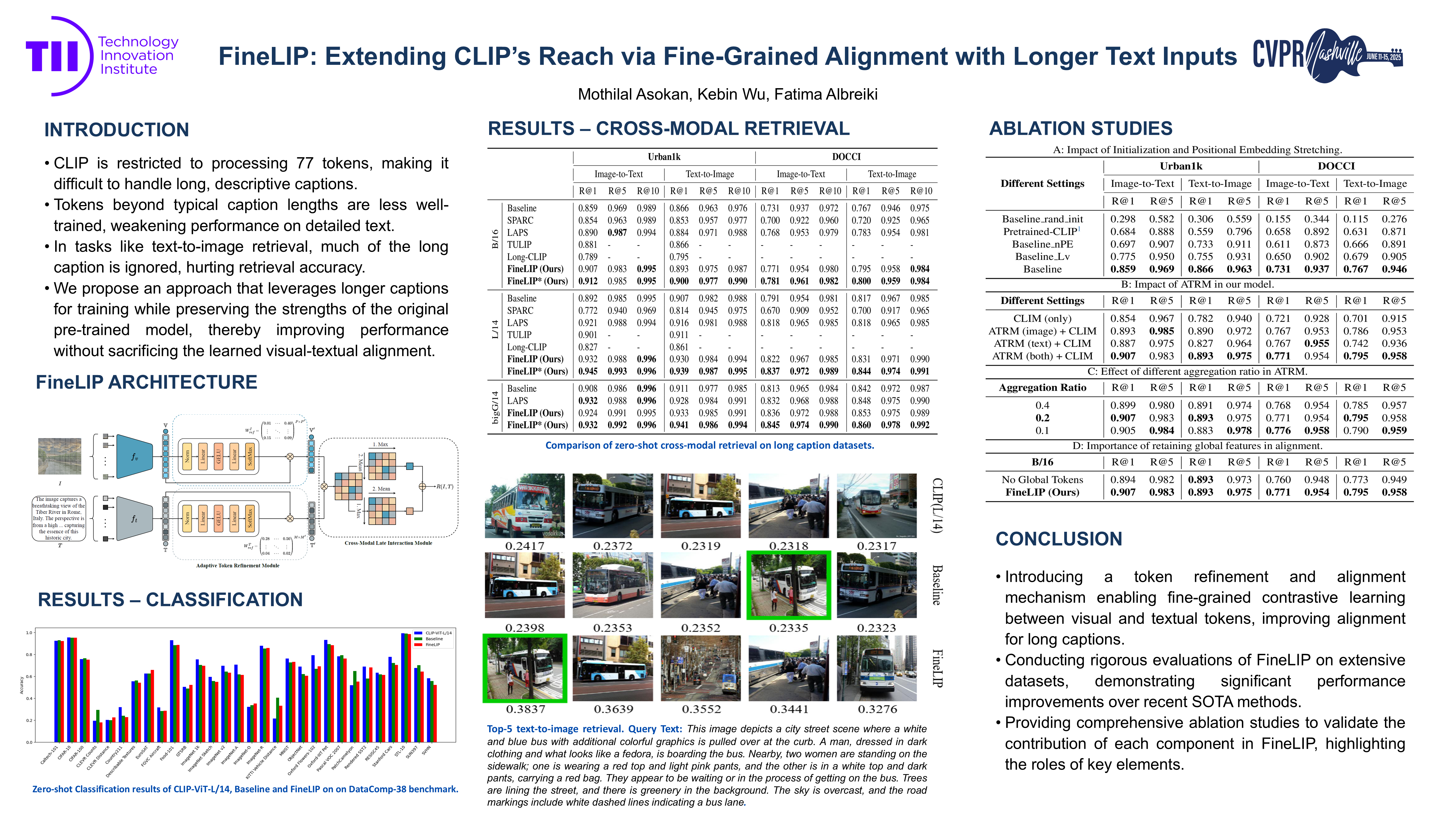
As a pioneering vision-language model, CLIP (Contrastive Language-Image Pre-training) has achieved significant success across various domains and a wide range of downstream vision-language tasks. However, the text encoders in popular CLIP models are limited to processing only 77 text tokens, which constrains their ability to effectively handle longer, detail-rich captions. Additionally, CLIP models often struggle to effectively capture detailed visual and textual information, which hampers their performance on tasks that require fine-grained analysis. To address these limitations, we present a novel approach, FineLIP, that extends the capabilities of CLIP. FineLIP enhances cross-modal text-image mapping by incorporating Fine-grained alignment with Longer text input within the CLIP-style framework. FineLIP first extends the positional embeddings to handle longer text, followed by the dynamic aggregation of local image and text tokens. The aggregated results are then used to enforce fine-grained token-to-token cross-modal alignment. We validate our model on datasets with long, detailed captions across two tasks: zero-shot cross-modal retrieval and text-to-image generation. Quantitative and qualitative experimental results demonstrate the effectiveness of FineLIP, outperforming existing state-of-the-art approaches. Furthermore, comprehensive ablation studies validate the benefits of key design elements within FineLIP.