Gen3DEval: Using vLLMs for Automatic Evaluation of Generated 3D Objects
{kind=link}
Abstract
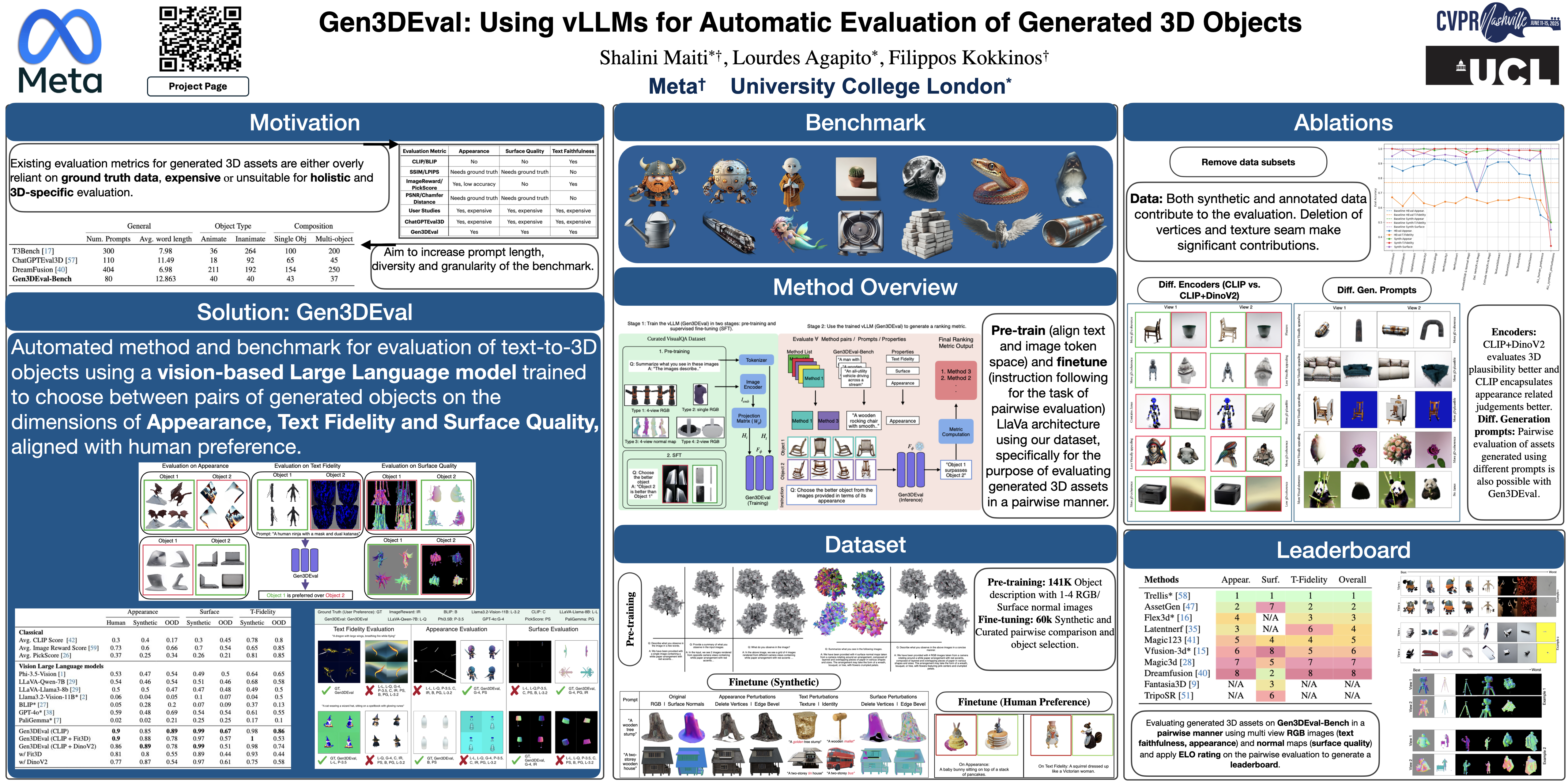
The rapid advancements in text-to-3D generation necessitate robust and scalable evaluation metrics that align closely with human judgment—a need unmet by current metrics such as PSNR and CLIP, which require ground-truth data or focus only on prompt fidelity. To address this, we introduce Gen3DEval, a novel evaluation framework that leverages vision large language models (vLLMs) specifically fine-tuned for 3D object quality assessment. Gen3DEval evaluates text fidelity, appearance, and surface quality—by analyzing 3D surface normals—without requiring ground-truth comparisons, bridging the gap between automated metrics and user preferences.Compared to state-of-the-art task-agnostic models, Gen3DEval demonstrates superior performance in user-aligned evaluations, establishing itself as a comprehensive and accessible benchmark for future research in text-to-3D generation. To support and encourage further research in this field, we will release both our code and benchmark, establishing Gen3DEval as a comprehensive and accessible tool for text-to-3D evaluation.