VISTA: Enhancing Long-Duration and High-Resolution Video Understanding by Video Spatiotemporal Augmentation
{kind=link}
Abstract
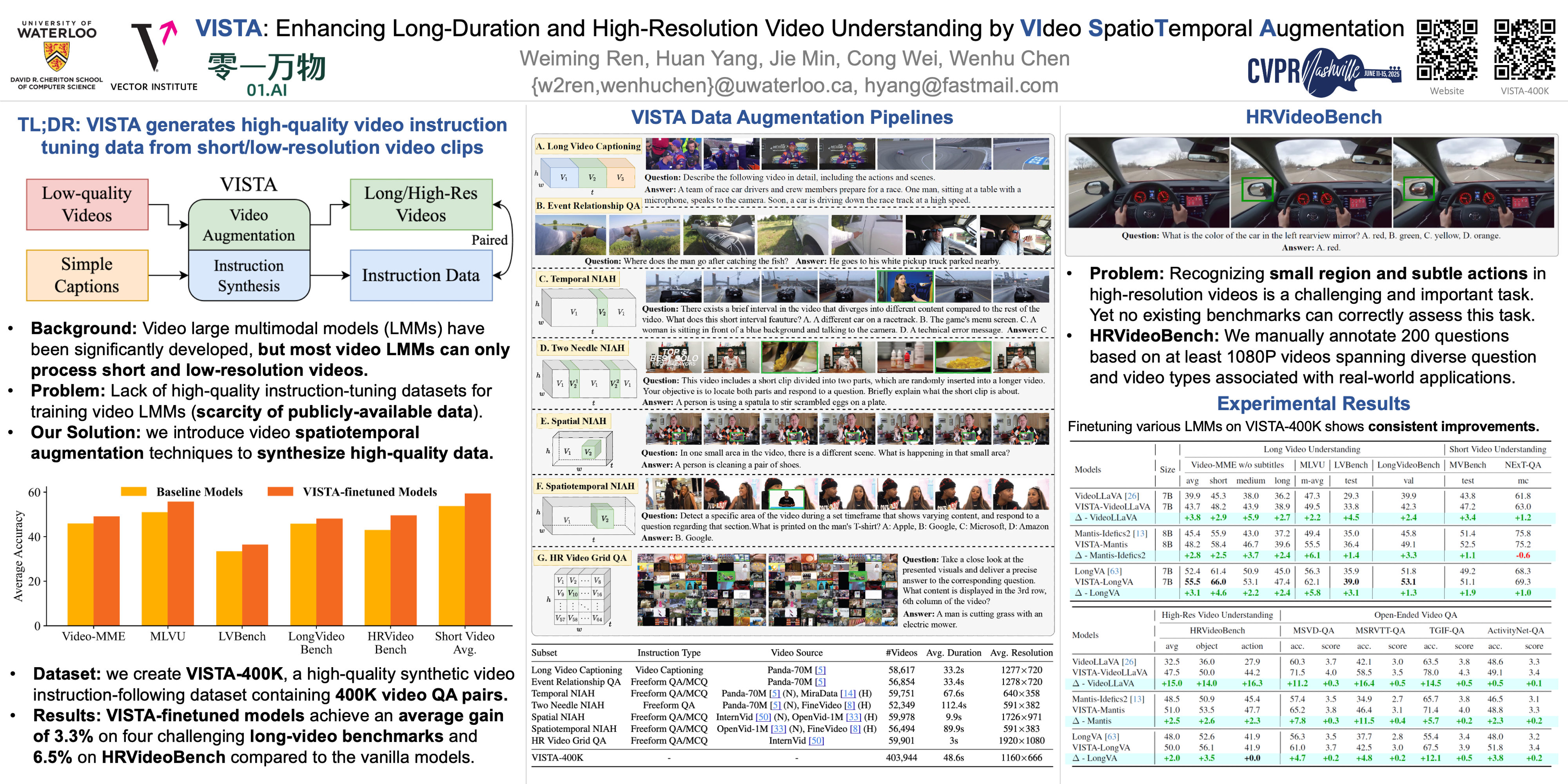
Current large multimodal models (LMMs) face significant challenges in processing and comprehending long-duration or high-resolution videos, which is mainly due to the lack of high-quality datasets. To address this issue from a data-centric perspective, we propose VISTA, a simple yet effective video spatiotemporal augmentation framework that synthesizes long-duration and high-resolution video instruction-following pairs from existing video-caption datasets. VISTA spatially and temporally combines videos to create new synthetic videos with extended durations and enhanced resolutions, and subsequently produces question-answer pairs pertaining to these newly synthesized videos. Based on this paradigm, we develop seven video augmentation methods and curate VISTA-400K, a video instruction-following dataset aimed at enhancing long-duration and high-resolution video understanding. Finetuning various video LMMs on our data resulted in an average improvement of 3.3% across four challenging benchmarks for long-video understanding. Furthermore, we introduce the first comprehensive high-resolution video understanding benchmark HRVideoBench, on which our finetuned models achieve a 6.5% performance gain. These results highlight the effectiveness of our framework. Our dataset, code and finetuned models will be released.