End-to-End HOI Reconstruction Transformer with Graph-based Encoding
 Highlight
Highlight
{kind=link}
Abstract
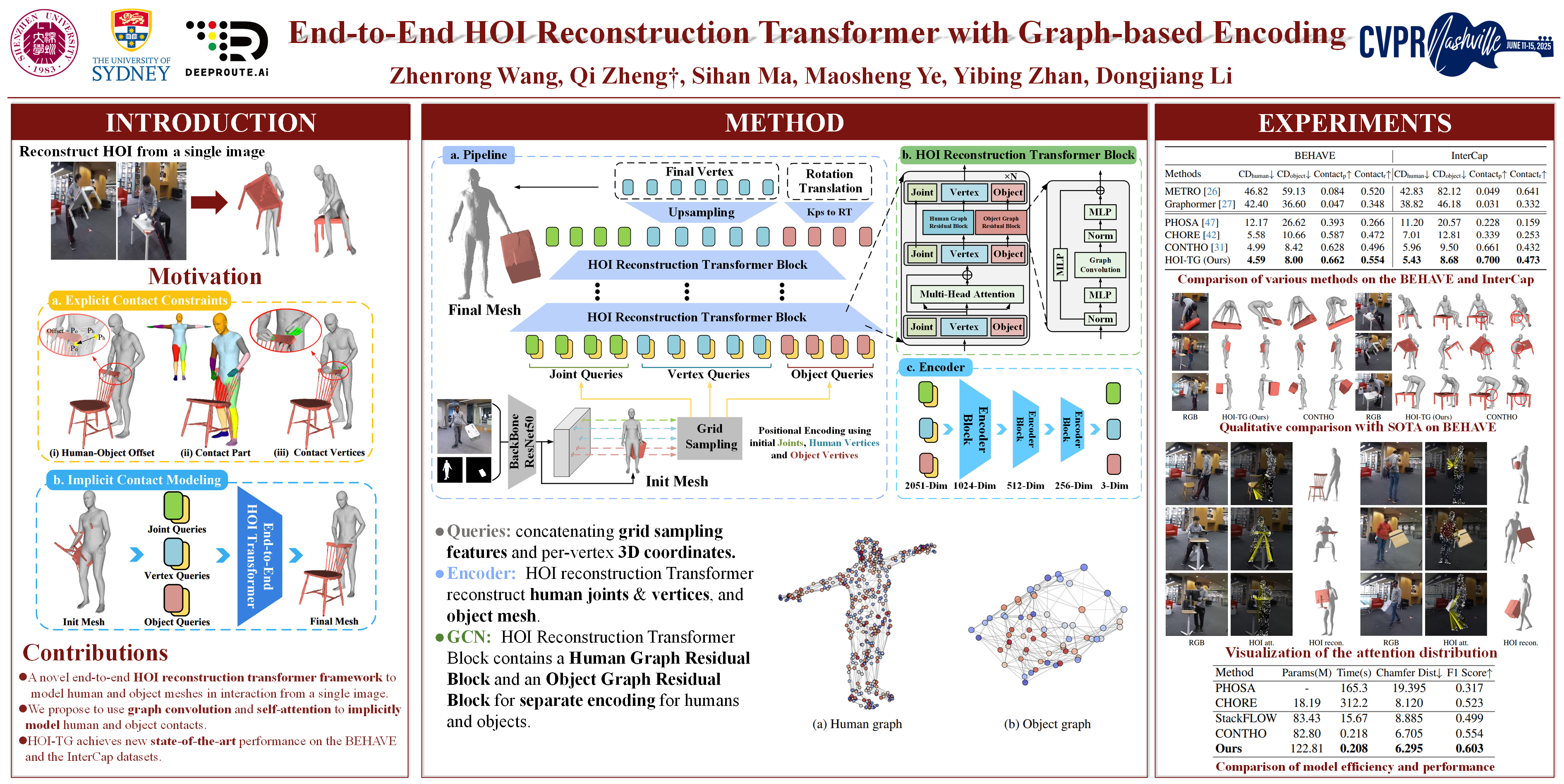
Human-object interaction (HOI) reconstruction has garnered significant attention due to its diverse applications and the success of capturing human meshes. Existing HOI reconstruction methods often rely on explicitly modeling interactions between humans and objects. However, such a way leads to a natural conflict between 3D mesh reconstruction, which emphasizes global structure, and fine-grained contact reconstruction, which focuses on local details. To address the limitations of explicit modeling, we propose the End-to-End HOI Reconstruction Transformer with Graph-based Encoding (HOI-TG). It implicitly learns the interaction between humans and objects by leveraging self-attention mechanisms. Within the transformer architecture, we devise graph residual blocks to aggregate the topology among vertices of different spatial structures. This dual focus effectively balances global and local representations. Without bells and whistles, HOI-TG achieves state-of-the-art performance on BEHAVE and InterCap datasets. Particularly on the challenging InterCap dataset, our method improves the reconstruction results for human and object meshes by 8.9% and 8.6%, respectively.