VisionArena: 230k Real World User-VLM Conversations with Preference Labels
{kind=link}
Abstract
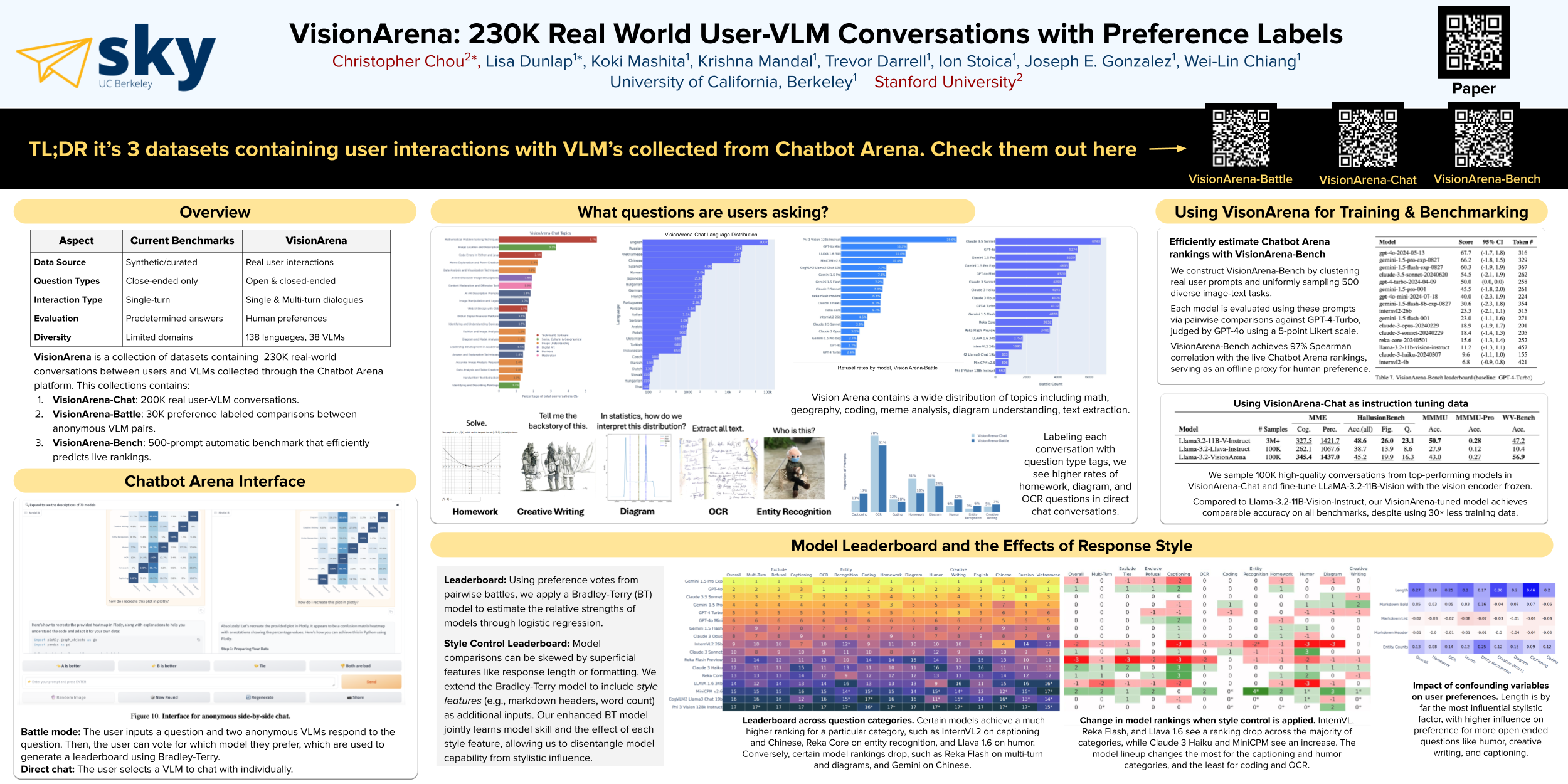
The growing adoption and capabilities of vision-language models (VLMs) demand benchmarks that reflect real-world user interactions. We introduce VisionArena, the largest existing dataset of crowdsourced real-world conversations between users and VLMs. While most visual question-answering datasets focus on close-ended problems or synthetic scenarios, VisionArena contains a wide variety of closed and open ended problems across 230K conversations, 73K unique users, 138 languages, and 45 VLMs. VisionArena consists of VisionArena-Chat, a set of 200k single-turn and multi-turn chat logs with a VLM, VisionArena-Battle, a set of 30K conversations between a user and 2 anonymous VLMs with preference votes, and VisionArena-Bench, an automatic benchmark consisting of 500 diverse user prompts which can be used to cheaply approximate model rankings.We analyze these datasets and highlight the types of question asked by users, the influence of style on user preference, and areas where models often fall short. We find that more open-ended questions like captioning and humor are heavily influenced by style, which causes certain models like Reka Flash and InternVL which are tuned for style to perform significantly better on these categories compared to other categories. We show that VisionArena-Chat and VisionArena-Battle can be used for post-training to align VLMs to human preferences through supervised fine-tuning. Compared to the popular instruction tuning dataset Llava-Instruct-158K, finetuning the same base model on VisionArena results in a a 17 point improvement on MMMU and a 46 point improvement on the WildVision human preference benchmark. Lastly, we show that running automatic VLM evaluation on VisionArena-Bench results in a model ranking which is largely consistent with major online preference benchmarks. We release both VisionArena and our finetuned model to further VLM development.