Perceptually Accurate 3D Talking Head Generation: New Definitions, Speech-Mesh Representation, and Evaluation Metrics
 Highlight
Highlight
{kind=link}
Abstract
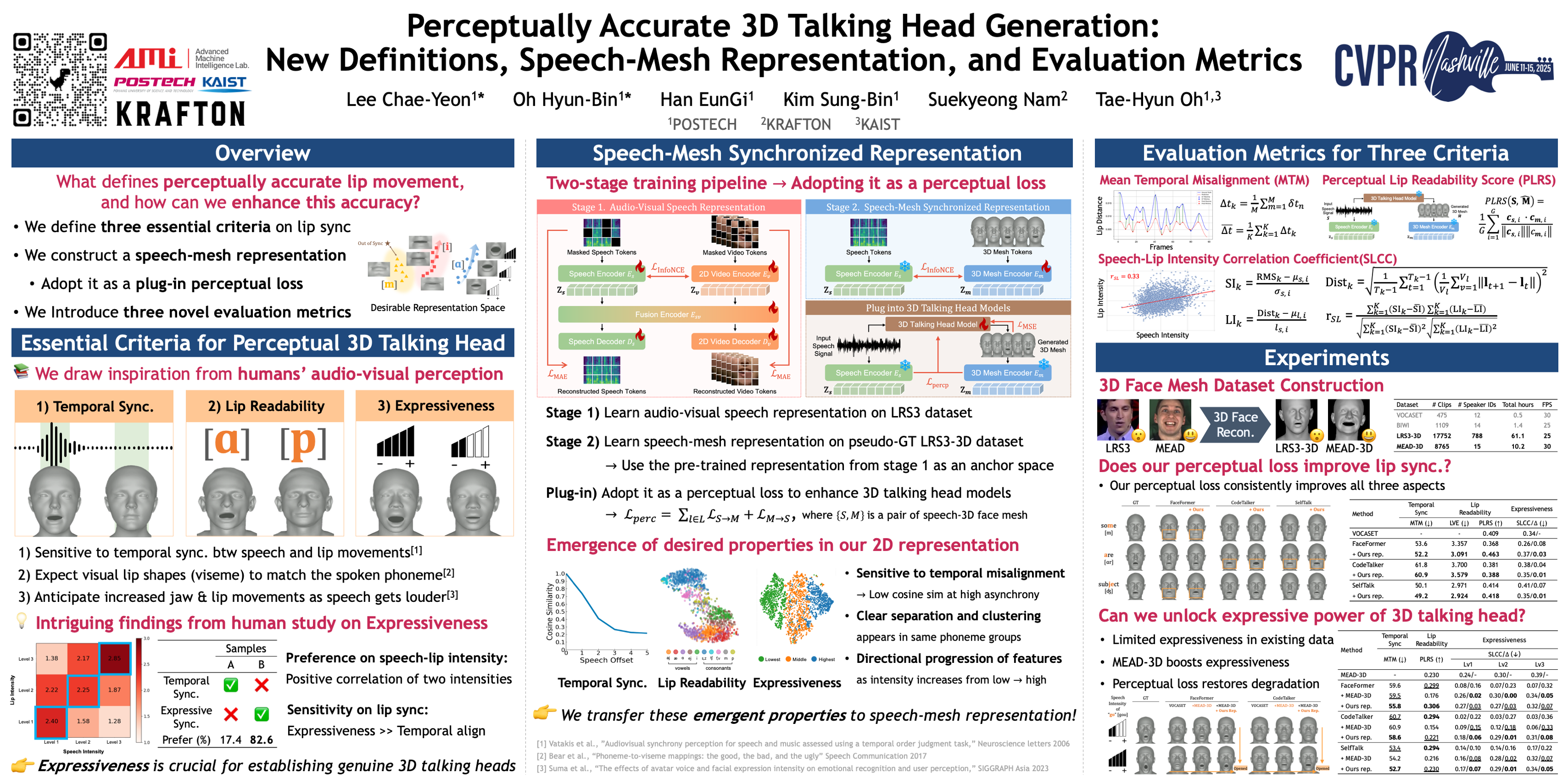
Recent advancements in speech-driven 3D talking head generation have achieved impressive advance in lip synchronization. However, existing models still fall short in capturing a perceptual alignment between diverse speech characteristics and lip movements. In this work, we define essential criteria—temporal synchronization, lip readability, and expressiveness— for perceptually accurate lip movements in response to speech signals. We also introduce a speech-mesh synchronized representation that captures the intricate correspondence between speech and facial mesh. We plug in this representation as a perceptual loss to guide lip movements, ensuring they are perceptually aligned with the given speech. Additionally, we utilize this representation as a perceptual metric and introduce two other physically-grounded lip synchronization metrics to evaluate these three criteria. Experiments demonstrate that training 3D talking head models with our perceptual loss significantly enhances all three aspects of perceptually accurate lip synchronization. Codes will be released if accepted.