Towards Universal AI-Generated Image Detection by Variational Information Bottleneck Network
{kind=link}
Abstract
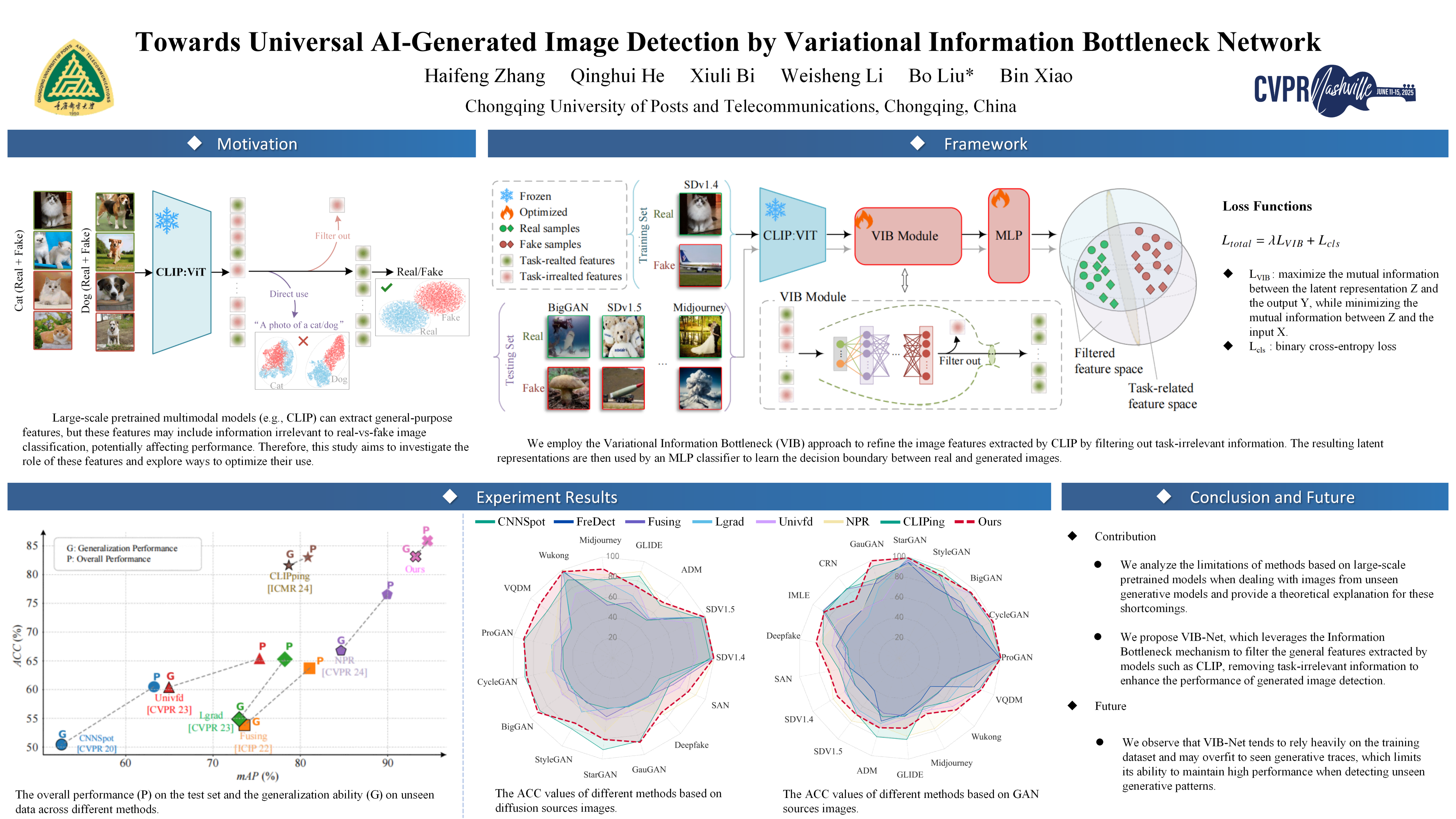
The rapid advancement of generative models has significantly improved the quality of generated images. Meanwhile, it challenges information authenticity and credibility. Current generated image detection methods based on large-scale pre-trained multimodal models have achieved impressive results. Although these models provide abundant features, the authentication task-related features are often submerged. Consequently, those authentication task-irrelated features cause models to learn superficial biases, thereby harming their generalization performance across different model genera (e.g., GANs and Diffusion Models). To this end, we proposed VIB-Net, which uses Variational Information Bottlenecks to enforce authentication task-related feature learning. We tested and analyzed the proposed method and existing methods on samples generated by 17 different generative models. Compared to SOTA methods, VIB-Net achieved a 4.62% improvement in mAP and a 9.33% increase in accuracy. Notably, in generalization tests on unseen generative models from different series, VIB-Net improved mAP by 12.48% and accuracy by 23.59% over SOTA methods.